graph TD
A[Inferences about<br/>Two Populations] --> B[Interval Estimation]
A --> C[Hypothesis Testing]
B --> B1[Independent<br/>Samples]
B --> B2[Paired<br/>Sampling]
B --> B3[Difference between<br/>Two Proportions]
B1 --> B1a[Estimation with<br/>Large Samples]
B1 --> B1b[Equal Variances -<br/>Pooled Data]
B1 --> B1c[Unequal<br/>Variances]
C --> C1[Independent<br/>Samples]
C --> C2[Paired<br/>Samples]
C --> C3[Tests for the<br/>Difference between<br/>Two Proportions]
C1 --> C1a[Tests with<br/>Large Samples]
C1 --> C1b[Equal Variances -<br/>Pooled Data]
C1 --> C1c[Unequal<br/>Variances]
style A fill:#333,stroke:#000,stroke-width:4px,color:#fff
style B fill:#fff,stroke:#000,stroke-width:3px
style C fill:#fff,stroke:#000,stroke-width:3px
10 Two-Population Inferences
Learning Objectives
After completing this chapter, you will be able to:
- Construct and interpret confidence intervals for the difference between two population means with large samples
- Apply pooled variance methods for small sample comparisons when population variances are equal
- Use adjusted degrees of freedom methods when population variances are unequal
- Implement paired-sample analysis for before-after or matched-pairs designs
- Estimate and test differences between two population proportions
- Determine appropriate sample sizes for two-population studies
- Conduct hypothesis tests comparing two means using independent samples
- Perform paired-sample hypothesis tests
- Test hypotheses about differences between two proportions
- Apply two-population inference methods to real business decision-making scenarios
10.1 Opening Scenario: U.S. Foreign Investment Strategy
NoteInternational Investment Analyst Challenge
Context: October 1996 - Fortune Magazine Analysis
Fortune magazine published a series of articles examining trends in U.S. foreign trade, focusing on massive international transactions and the competition between Europe and Asia for American investment dollars.
The Numbers:
- European Investment: $364 billion in 1996, up 17% from previous year’s record
- Asian Investment: Over $100 billion, representing 16% growth in U.S. commercial participation
The Debate:
These articles challenged conventional wisdom that U.S. companies preferred investing in Asia’s rapidly growing economies over Europe’s established markets. Instead, the analysis suggested American business interests still view Europe as offering more lucrative opportunities for corporate growth.
Your Role:
You are an international analyst for a major U.S. corporation. You must prepare a comprehensive comparative report on the advantages of investing in each geopolitical region. This report will be presented to division executives who will decide the future course of foreign investment for the coming years.
10.1.1 Your Analysis Requirements
To guide the investment decision, you must:
- Compare average return on investment in Europe versus Asia
- Determine which region has a lower percentage of failed investment projects
- Estimate average investment levels in both Europe and Asia
- Provide thorough comparison of all relevant financial measures in these two foreign markets
This chapter provides the statistical tools you’ll need to make these critical comparisons.
10.2 9.1 Introduction: Why Compare Two Populations?
Chapters 7 and 8 demonstrated how to construct confidence intervals and test hypotheses for a single population. However, many of the most important business questions require comparing two populations:
TipReal-World Comparison Questions
Manufacturing: - What’s the difference, if any, between the average durability of ski boots made by North Slope versus those produced by Head?
Operations: - Do workers in Plant A produce more on average than workers in Plant B?
Quality Control: - Is there a difference between the proportion of defective units produced by Method 1 versus Method 2?
Marketing: - Does advertising campaign A generate more sales than campaign B?
Human Resources: - Are employee satisfaction scores higher after implementing a new policy?
Finance: - Do European investments yield higher returns than Asian investments?
10.2.1 Two Fundamental Sampling Approaches
The exact statistical procedure depends on the sampling technique used:
1. Independent Samples
As the name indicates, independent sampling involves collecting separate, unrelated samples from each population.
- Samples don’t need to be the same size
- Observations in one sample have no relationship to observations in the other
- Example: Comparing durability of 100 Brand A tires versus 80 Brand B tires
2. Paired Samples (Matched Pairs)
With paired sampling, observations from each population are matched or correspond to each other.
- Observations are paired based on similarity in relevant characteristics
- Also called “before-after” comparisons when measuring same units twice
- Example: Measuring employee productivity before and after training
We’ll begin with independent sampling methods.
10.3 9.2 Interval Estimation for Independent Samples
When comparing two populations, we’re interested in estimating the difference between two population means: (\mu_1 - \mu_2)
The appropriate method depends on the sample sizes n_1 and n_2:
- Large samples (both n_1 \geq 30 and n_2 \geq 30): Use Z-distribution
- Small samples (either n_1 < 30 or n_2 < 30): Use t-distribution
10.3.1 A. Estimation with Large Samples (n₁ ≥ 30 and n₂ ≥ 30)
Point Estimate:
The point estimate of the difference (\mu_1 - \mu_2) is the difference between sample means:
\bar{X}_1 - \bar{X}_2
Sampling Distribution:
When both n_1 and n_2 are large, the sampling distribution of differences (\bar{X}_1 - \bar{X}_2) follows a normal distribution centered at (\mu_1 - \mu_2).
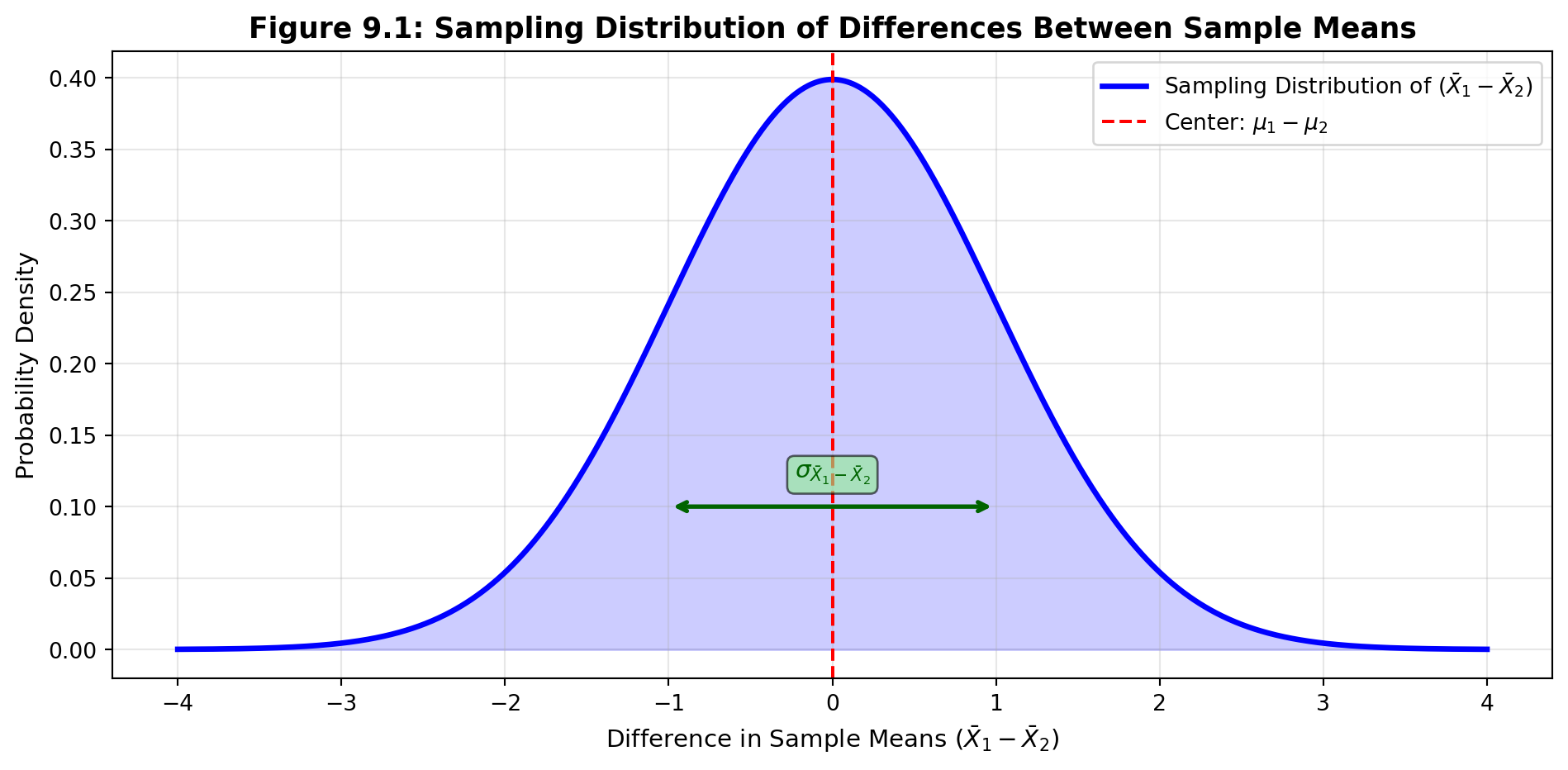
Standard Error of the Difference:
The standard error measures how much the differences between sample means tend to vary:
In practice, population variances are usually unknown. We estimate them using sample variances:
s_{\bar{X}_1 - \bar{X}_2} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}
Confidence Interval Formula:
ImportantConfidence Interval for (\mu_1 - \mu_2) — Large Samples
\text{C.I. for } (\mu_1 - \mu_2) = (\bar{X}_1 - \bar{X}_2) \pm Z \cdot s_{\bar{X}_1 - \bar{X}_2}
Where: - (\bar{X}_1 - \bar{X}_2) = point estimate - Z = critical Z-value for desired confidence level - s_{\bar{X}_1 - \bar{X}_2} = estimated standard error
Important Note: We’re not interested in the individual values of \mu_1 or \mu_2, but only in their difference.
10.3.2 Example: Transfer Trucking Route Comparison
Scenario: Delivery Time Analysis
Transfer Trucking transports shipments between Chicago and Kansas City using two different routes. The dispatcher, Delmar, wants to determine if there’s a difference in average transit times.
Sample Data:
| Route | Sample Size | Mean Time | Std Dev |
|---|---|---|---|
| North | n = 100 | \bar{X}_N = 17.2 hrs | s_N = 5.3 hrs |
| South | n = 75 | \bar{X}_S = 19.4 hrs | s_S = 4.5 hrs |
Objective: Develop a 95% confidence interval for the difference in average transit time.
Solution:
Step 1: Calculate Standard Error
Since population standard deviations are unknown, we use the sample standard deviations:
s_{\bar{X}_N - \bar{X}_S} = \sqrt{\frac{s_N^2}{n_N} + \frac{s_S^2}{n_S}} = \sqrt{\frac{(5.3)^2}{100} + \frac{(4.5)^2}{75}}
= \sqrt{\frac{28.09}{100} + \frac{20.25}{75}} = \sqrt{0.2809 + 0.27} = \sqrt{0.5509} = 0.742 \text{ hours}
Step 2: Find Critical Value
For 95% confidence level: Z = 1.96
Step 3: Compute Confidence Interval
\text{C.I.} = (\bar{X}_N - \bar{X}_S) \pm Z \cdot s_{\bar{X}_N - \bar{X}_S}
= (17.2 - 19.4) \pm (1.96)(0.742)
= -2.2 \pm 1.45
-3.65 \leq (\mu_N - \mu_S) \leq -0.75
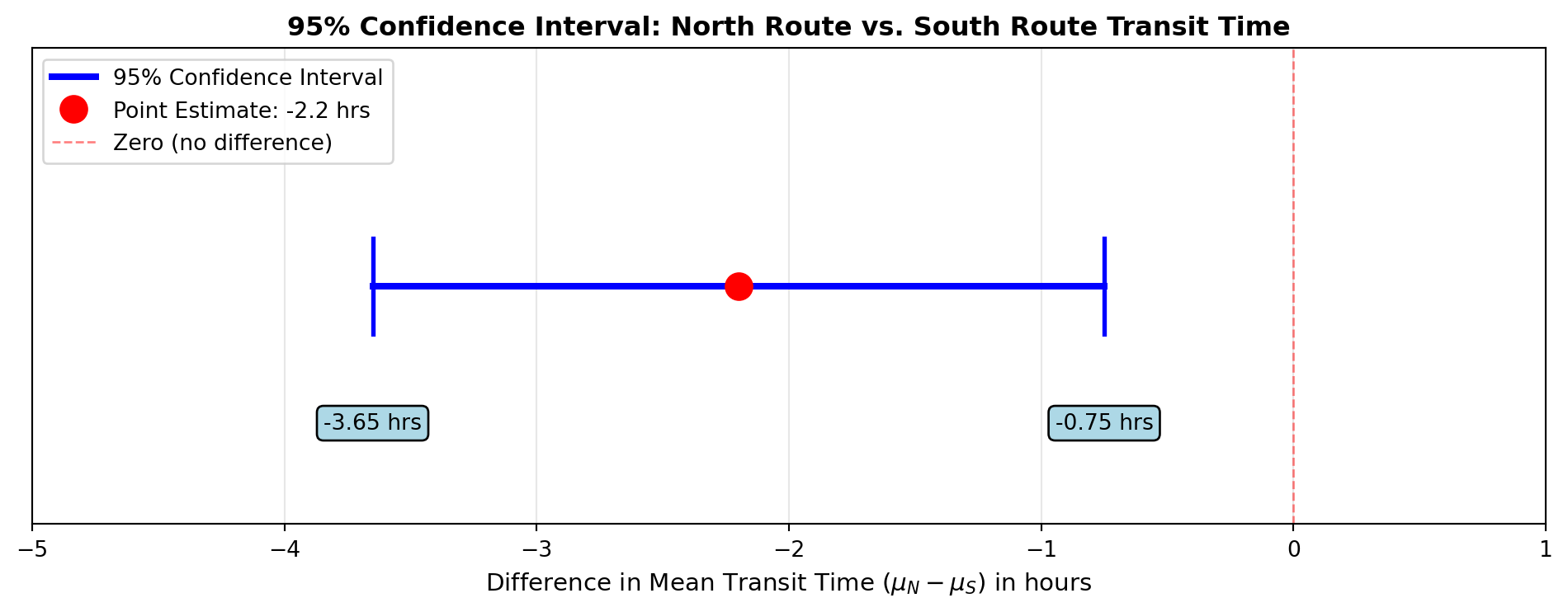
Interpretation:
The results can be interpreted two ways:
Technical: Delmar can be 95% confident that (\mu_N - \mu_S) is between -3.65 hours and -0.75 hours.
Practical: Since we subtracted the South route mean from the North route mean and got negative numbers, Delmar can be 95% confident that the South route takes between 0.75 and 3.65 hours longer than the North route.
Business Decision: The North route is consistently faster. If minimizing transit time is important, Transfer Trucking should prioritize the North route.
10.4 Section Exercises: Large Sample Confidence Intervals
1. Clark Insurance Claims Analysis: Clark Insurance sells policies to residents throughout the Chicago area. The owner wants to estimate the difference in average claims between people living in urban zones versus those in suburbs.
- Urban sample: n = 180, \bar{X} = $2,025, s = $918
- Suburban sample: n = 200, \bar{X} = $1,802, s = $512
What does a 95% confidence interval tell the owner about average claims filed by these two groups?
2. Steel Tube Production Comparison: Two production processes are used to produce steel tubes.
- Process 1: n = 100, \bar{X} = 27.3 inches, s = 10.3 inches
- Process 2: n = 100, \bar{X} = 30.1 inches, s = 5.2 inches
What does a 99% confidence interval reveal about the difference in average lengths of tubes produced by these two methods?
3. Chapman Industries Phone System Comparison: Chuck Chapman wants to determine if customers calling one phone system are kept on hold longer on average than those calling another system.
- System 1: n = 75, \bar{X} = 25.2 seconds, s = 4.8 seconds
- System 2: n = 70, \bar{X} = 21.3 seconds, s = 3.8 seconds
What recommendation would you provide to Chuck based on a 90% confidence interval estimating the difference in average wait times if he wants to minimize customer wait time?
4. Production Design Time Comparison: Two production designs are used to manufacture a certain product.
- Old design: n = 150, \bar{X} = 3.51 days, s = 0.79 days
- New design: n = 150, \bar{X} = 3.32 days, s = 0.73 days
What does a 99% confidence interval reveal about the difference between average times required to make the product? Which design should be used?
5. Conceptual Question: Explain exactly what the standard error of the difference between sample means actually measures.
End of Stage 1
This completes the first stage covering: - Introduction to two-population comparisons - Opening scenario (U.S. foreign investment strategy) - Large sample confidence intervals for independent samples - Standard error calculation - Complete worked example with interpretation - Section exercises
Coming in Stage 2: - Small sample methods (t-distribution) - Pooled variance approach (equal variances) - Separate variance approach (unequal variances) - More comprehensive examples # Two-Population Inferences - Stage 2
10.5 9.2B Estimation with Small Samples: The t-Distribution
When either sample is small (n < 30), we cannot assume that the distribution of differences (\bar{X}_1 - \bar{X}_2) follows a normal distribution. Therefore, we cannot use the Z-distribution.
Requirements for Using t-Distribution:
- Populations are normally distributed (or approximately normal)
- Population variances are unknown
When these conditions are met, we must use the t-distribution.
10.5.1 Critical Question: Are the Variances Equal?
An important consideration is whether the two population variances are equal (\sigma_1^2 = \sigma_2^2).
We’ll examine two approaches:
- Equal variances (\sigma_1^2 = \sigma_2^2): Use pooled variance method
- Unequal variances (\sigma_1^2 \neq \sigma_2^2): Use separate variance method with adjusted degrees of freedom
10.5.2 1. Equal Variances: Pooled Variance Method
When population variances are equal, there exists some common variance \sigma^2 shared by both populations:
\sigma_1^2 = \sigma_2^2 = \sigma^2
However, due to sampling error, the two sample variances s_1^2 and s_2^2 will likely differ from each other and from the common \sigma^2.
Solution: Pool the data from both samples to obtain a single estimate of \sigma^2.
ImportantPooled Variance Formula
s_p^2 = \frac{s_1^2(n_1 - 1) + s_2^2(n_2 - 1)}{n_1 + n_2 - 2}
This is a weighted average of the two sample variances, where the weights are the degrees of freedom (n - 1) for each sample.
Degrees of freedom: df = n_1 + n_2 - 2
Confidence Interval Formula:
10.5.3 Example: Vending Machine Beverage Dispenser
Scenario: Quality Control for Student Cafeteria
A vending machine in the student cafeteria dispenses beverages into paper cups. The facilities manager wants to know if a recent machine adjustment changed the average fill amount.
Sample Data:
| Timing | Sample Size | Mean | Variance |
|---|---|---|---|
| Before adjustment | n₁ = 15 | \bar{X}_1 = 15.3 oz | s_1^2 = 3.5 |
| After adjustment | n₂ = 10 | \bar{X}_2 = 17.1 oz | s_2^2 = 3.9 |
Assumptions: - Variance \sigma^2 is constant before and after adjustment - Dispensed amounts are normally distributed
Objective: Construct a 95% confidence interval for the difference in average fill amounts.
Solution:
Step 1: Calculate Pooled Variance
s_p^2 = \frac{s_1^2(n_1 - 1) + s_2^2(n_2 - 1)}{n_1 + n_2 - 2}
= \frac{3.5(14) + 3.9(9)}{15 + 10 - 2} = \frac{49 + 35.1}{23} = \frac{84.1}{23} = 3.66
Step 2: Find Critical t-Value
- Confidence level: 95% → α = 0.05
- Degrees of freedom: df = n_1 + n_2 - 2 = 15 + 10 - 2 = 23
- From t-table: t_{0.025, 23} = 2.069
Step 3: Calculate Confidence Interval
\text{C.I.} = (\bar{X}_1 - \bar{X}_2) \pm t \sqrt{s_p^2 \left(\frac{1}{n_1} + \frac{1}{n_2}\right)}
= (15.3 - 17.1) \pm 2.069 \sqrt{3.66 \left(\frac{1}{15} + \frac{1}{10}\right)}
= -1.8 \pm 2.069 \sqrt{3.66(0.0667 + 0.1)} = -1.8 \pm 2.069\sqrt{3.66 \times 0.1667}
= -1.8 \pm 2.069\sqrt{0.6103} = -1.8 \pm 2.069(0.781) = -1.8 \pm 1.61
-3.41 \leq (\mu_1 - \mu_2) \leq -0.19
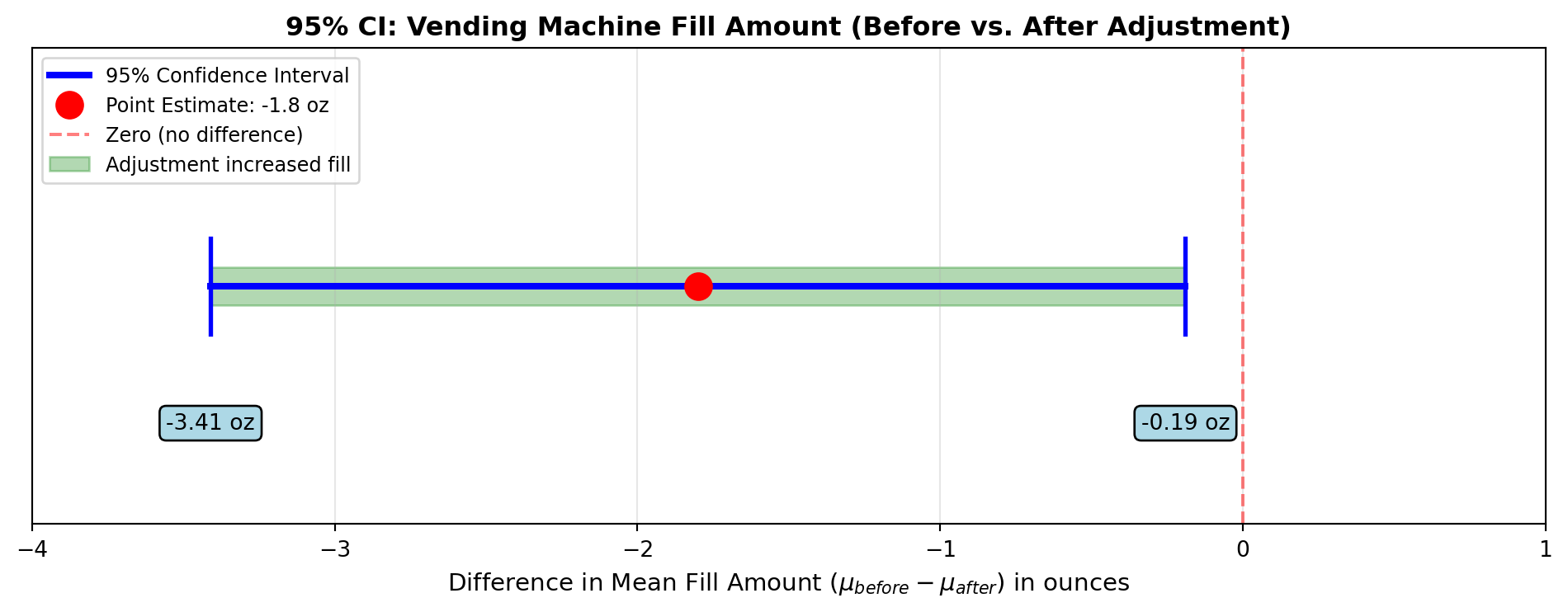
Interpretation:
Subtracting the after-adjustment mean (17.1 oz) from the before-adjustment mean (15.3 oz) produces negative values for both endpoints.
Conclusion: We can be 95% confident that the adjustment increased the average fill level by between 0.19 and 3.41 ounces.
The interval does not contain zero, confirming a real change occurred.
10.5.4 Example 9.2: Labor Negotiations — Atlanta vs. Newport News
Scenario: Wage Equity Analysis
Labor negotiations between your company and the workers’ union are on the verge of breaking down. There’s considerable disagreement about average wage levels between workers at the Atlanta plant and the Newport News, Virginia plant.
Background: - Wages were set by the old labor agreement three years ago - Wages are based strictly on seniority - Contract tightly controls wages → variance is same at both plants ✓ - Wages are normally distributed ✓ - Different seniority patterns → different average wages suspected
Your Task:
The management negotiator wants you to develop a 98% confidence interval to estimate the difference between average wage levels. If a difference exists, adjustments must be made to bring lower wages up to match higher wages.
Sample Data:
| Atlanta Plant | Newport News Plant | |
|---|---|---|
| Sample size | n_A = 23 | n_N = 19 |
| Sample mean | \bar{X}_A = \$17.53/hr | \bar{X}_N = \$15.50/hr |
| Sample variance | s_A^2 = 92.10 | s_N^2 = 87.10 |
Solution:
Step 1: Calculate Pooled Variance
s_p^2 = \frac{s_A^2(n_A - 1) + s_N^2(n_N - 1)}{n_A + n_N - 2}
= \frac{92.10(22) + 87.10(18)}{23 + 19 - 2} = \frac{2026.2 + 1567.8}{40} = \frac{3594}{40} = 89.85
Step 2: Find Critical t-Value
- α = 0.02 (98% confidence level)
- df = 23 + 19 - 2 = 40
- From t-table: t_{0.01, 40} = 2.423
Step 3: Calculate Confidence Interval
\text{C.I.} = (\bar{X}_A - \bar{X}_N) \pm t \sqrt{s_p^2 \left(\frac{1}{n_A} + \frac{1}{n_N}\right)}
= (17.53 - 15.50) \pm 2.423 \sqrt{89.85 \left(\frac{1}{23} + \frac{1}{19}\right)}
= 2.03 \pm 2.423 \sqrt{89.85(0.0435 + 0.0526)} = 2.03 \pm 2.423\sqrt{89.85 \times 0.0961}
= 2.03 \pm 2.423\sqrt{8.635} = 2.03 \pm 2.423(2.939) = 2.03 \pm 7.12
-5.09 \leq (\mu_A - \mu_N) \leq 9.15
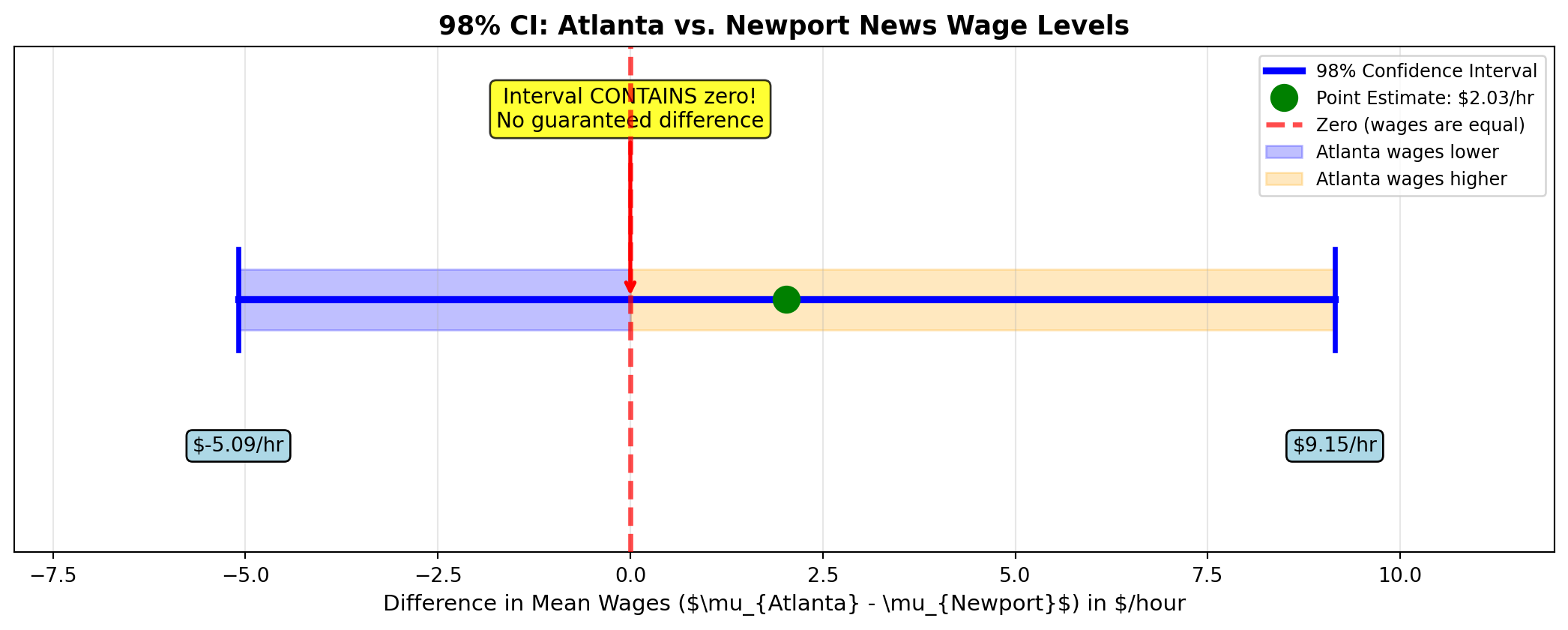
Interpretation:
We can be 98% confident that the average Atlanta wage is between: - $5.09 less than Newport News wages, OR - $9.15 more than Newport News wages
ImportantCritical Finding: Interval Contains Zero
Because this interval contains $0, we can be 98% confident that no difference exists in average wages between the two plants.
Business Recommendation: No wage adjustment is warranted. The apparent difference of $2.03/hr could easily be due to sampling variation rather than a true population difference.
10.6 2. Unequal Variances: Separate Variance Method
When population variances are unequal (\sigma_1^2 \neq \sigma_2^2), or there’s no evidence to assume equality, the pooled variance method doesn’t apply.
The Challenge:
The distribution of (\bar{X}_1 - \bar{X}_2) doesn’t follow a t-distribution with n_1 + n_2 - 2 degrees of freedom. No exact distribution has been found, only approximations.
The Solution:
Use a modified t-statistic (t') with adjusted degrees of freedom.
Confidence Interval Formula:
ImportantC.I. for (\mu_1 - \mu_2) with Unequal Variances
\text{C.I. for } (\mu_1 - \mu_2) = (\bar{X}_1 - \bar{X}_2) \pm t' \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}
Where: - t' = critical t-value with adjusted df - No pooling of variances
10.6.1 Example: IBM Executive Training Programs
Scenario: Wall Street Journal Report
The Wall Street Journal described two training programs used by IBM. A comparison is needed to determine if one program is more effective.
Sample Data:
| Program | Sample Size | Mean Score | Variance |
|---|---|---|---|
| Program 1 | n₁ = 12 | \bar{X}_1 = 73.5 | s_1^2 = 100.2 |
| Program 2 | n₂ = 15 | \bar{X}_2 = 79.8 | s_2^2 = 121.3 |
Note: Variances appear different → use separate variance method
Objective: Construct a 95% confidence interval for the difference in average scores.
Solution:
Step 1: Calculate Adjusted Degrees of Freedom
\text{df} = \frac{\left(\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}\right)^2}{\frac{(s_1^2/n_1)^2}{n_1 - 1} + \frac{(s_2^2/n_2)^2}{n_2 - 1}}
= \frac{\left(\frac{100.2}{12} + \frac{121.3}{15}\right)^2}{\frac{(100.2/12)^2}{11} + \frac{(121.3/15)^2}{14}}
= \frac{(8.35 + 8.087)^2}{\frac{(8.35)^2}{11} + \frac{(8.087)^2}{14}} = \frac{(16.437)^2}{\frac{69.72}{11} + \frac{65.40}{14}}
= \frac{270.18}{6.338 + 4.671} = \frac{270.18}{11.009} = 24.55
Round down: df = 24
Step 2: Find Critical t’-Value
- 95% confidence level
- df = 24
- From t-table: t'_{0.025, 24} = 2.064
Step 3: Calculate Confidence Interval
\text{C.I.} = (\bar{X}_1 - \bar{X}_2) \pm t' \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}
= (73.5 - 79.8) \pm 2.064 \sqrt{\frac{100.2}{12} + \frac{121.3}{15}}
= -6.3 \pm 2.064 \sqrt{8.35 + 8.087} = -6.3 \pm 2.064\sqrt{16.437}
= -6.3 \pm 2.064(4.054) = -6.3 \pm 8.36
-14.66 \leq (\mu_1 - \mu_2) \leq 2.06
Interpretation:
Because the interval contains zero, there’s no strong evidence of a difference in training program effectiveness. Either program appears equally suitable for training IBM executives.
10.6.2 Example 9.3: Acme Ltd. Rubber Shock Absorbers
Scenario: Product Durability Comparison
Acme Ltd. sells two types of rubber shock absorbers for baby carriages. Wear tests measure durability.
Sample Data:
| Type | Sample Size | Mean Duration | Std Dev |
|---|---|---|---|
| Type 1 | n₁ = 13 | \bar{X}_1 = 11.3 weeks | s₁ = 3.5 weeks |
| Type 2 | n₂ = 10 | \bar{X}_2 = 7.5 weeks | s₂ = 2.7 weeks |
Business Context: - Type 1 is more expensive to manufacture - CEO will only use Type 1 if it lasts at least 8 weeks longer than Type 2 - CEO tolerates only 2% probability of error (α = 0.02) - No evidence that variances are equal → use separate variance method
Solution:
Step 1: Calculate Adjusted Degrees of Freedom
\text{df} = \frac{\left[\frac{(3.5)^2}{13} + \frac{(2.7)^2}{10}\right]^2}{\frac{[(3.5)^2/13]^2}{12} + \frac{[(2.7)^2/10]^2}{9}}
= \frac{\left[\frac{12.25}{13} + \frac{7.29}{10}\right]^2}{\frac{(0.942)^2}{12} + \frac{(0.729)^2}{9}}
= \frac{(0.942 + 0.729)^2}{\frac{0.887}{12} + \frac{0.531}{9}} = \frac{(1.671)^2}{0.0739 + 0.059}
= \frac{2.792}{0.1329} = 20.99 \approx 20 \text{ (round down)}
Step 2: Find Critical t’-Value
- 98% confidence level (α = 0.02)
- df = 20
- From t-table: t'_{0.01, 20} = 2.528
Step 3: Calculate Confidence Interval
\text{C.I.} = (11.3 - 7.5) \pm 2.528 \sqrt{\frac{(3.5)^2}{13} + \frac{(2.7)^2}{10}}
= 3.8 \pm 2.528 \sqrt{0.942 + 0.729} = 3.8 \pm 2.528\sqrt{1.671}
= 3.8 \pm 2.528(1.293) = 3.8 \pm 3.3
0.5 \leq (\mu_1 - \mu_2) \leq 7.1 \text{ weeks}
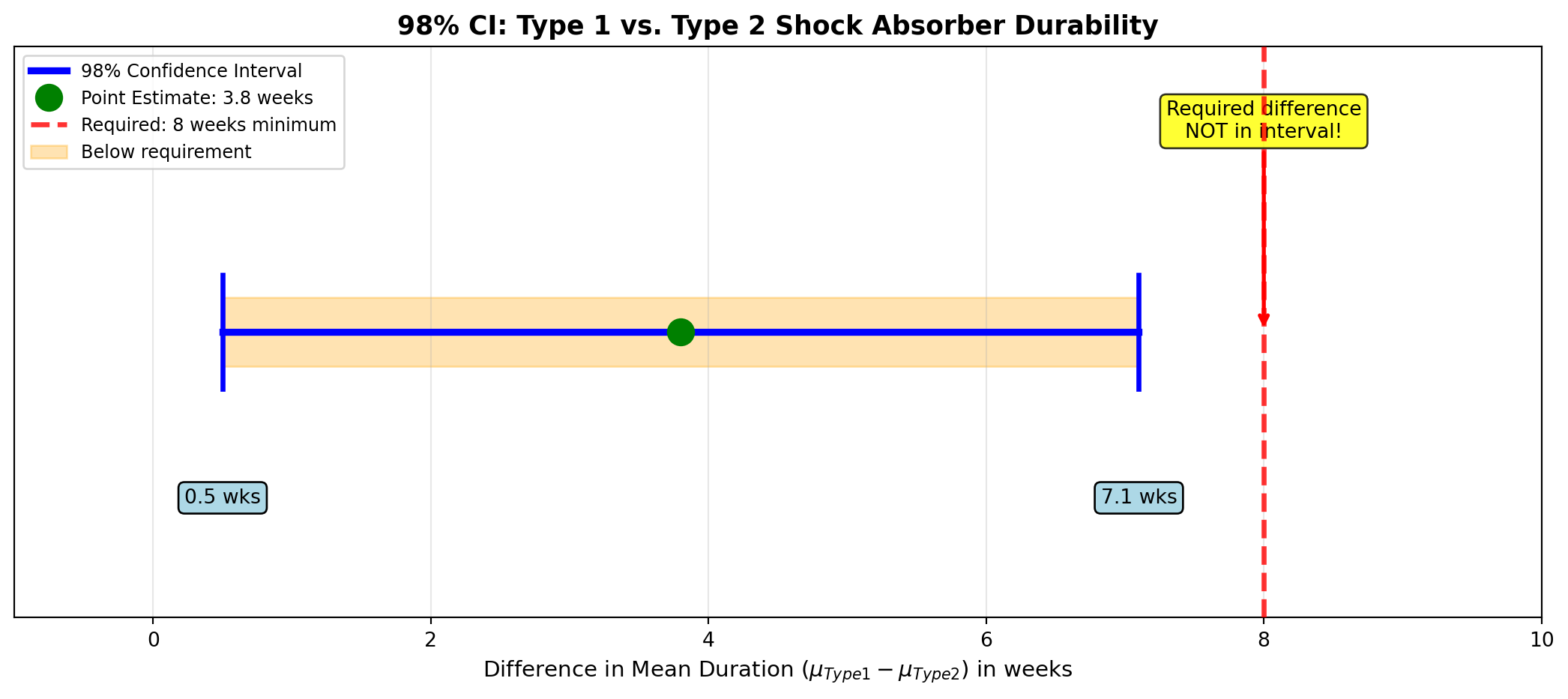
Interpretation:
Acme can be 98% confident that Type 1 lasts between 0.5 and 7.1 weeks longer than Type 2.
WarningBusiness Decision: Do NOT Use Type 1
The required difference of 8 weeks is NOT in the interval. Even at the upper limit (7.1 weeks), Type 1 doesn’t meet the CEO’s criterion.
Recommendation: Continue using Type 2 (the less expensive option) since Type 1 doesn’t provide sufficient additional durability to justify its higher manufacturing cost.
10.7 Section Exercises: Small Sample Confidence Intervals
6. Conceptual Question: What conditions must the t-distribution meet before it can be used for two-population inference?
7. Croc Aid vs. Energy Pro: Seventeen cans of Croc Aid show a mean of 17.2 ounces with a standard deviation of 3.2 ounces, and 13 cans of Energy Pro produce a mean of 18.1 ounces and s = 2.7 ounces. Assuming equal variances and normal distributions in population weights, what conclusions can be drawn regarding the difference in average weights based on a 98% confidence interval?
8. Grow-rite Fertilizer Complaint: Grow-rite sells commercial fertilizer produced in two plants (Atlanta and Dallas). Recent customer complaints suggest Atlanta shipments are underweight compared to Dallas shipments. If 10 boxes from Atlanta average 96.3 pounds with s = 12.5, and 15 boxes from Dallas average 101.1 with s = 10.3, does a 99% confidence interval confirm this complaint? Assume equal variances.
9. Opus Gold Extraction: Opus, Inc. has developed a process for producing gold from seawater. Fifteen gallons from the Pacific Ocean produced a mean of 12.7 ounces of gold per gallon with s = 4.2 ounces, and 12 gallons from the Atlantic Ocean produced similar figures of 15.9 and 1.7. Based on a 95% interval, what is your estimate of the difference in average ounces of gold from these two sources? There’s no reason to assume variances are equal.
10. Ralphie’s Apartment Search: Ralphie starts college next fall. He samples apartments on the north and south ends of the city to see if there’s a difference in average rents.
- North apartments: $600, $650, $530, $800, $750, $700, $750
- South apartments: $500, $450, $800, $650, $500, $500, $450, $400
If there’s no evidence that variances are equal, what does a 99% interval tell Ralphie about the difference in average rents?
11. Bigelow Products Sales Comparison: Bigelow Products wants to develop a 95% interval to estimate the difference in average weekly sales in two target markets. A sample of 9 weeks in market 1 produced a mean and standard deviation (in hundreds of dollars) of 5.72 and 1.008 respectively. Comparable figures for market 2, based on a sample of 10 weeks, were 8.72 and 1.208. Assuming equal variances, what results do they report?
12. U.S. Manufacturing Supplier Comparison: U.S. Manufacturing buys raw materials from two suppliers. Management is concerned about production delays from late shipment deliveries. A sample of 10 shipments from Supplier A have an average delivery time of 6.8 days and s = 2.57 days, while 12 shipments from Supplier B average 4.08 days and s = 1.93. If equal variances cannot be assumed, what recommendation would you make based on a 90% interval for the difference in average delivery times?
End of Stage 2
This completes the second stage covering: - Small sample confidence intervals using t-distribution - Pooled variance method (equal variances assumed) - Separate variance method (unequal variances) - Adjusted degrees of freedom calculation (Welch-Satterthwaite) - Multiple worked examples with business interpretations - Python visualizations of confidence intervals - 7 comprehensive section exercises
Coming in Stage 3: - Paired samples (matched pairs) analysis - Confidence intervals for difference between two proportions - Sample size determination - Complete examples and exercises # Two-Population Inferences - Stage 3
10.8 9.3 Paired Samples: Matched Pairs Analysis
In the previous sections, we examined independent samples—observations from one population are completely unrelated to observations from the second population. Now we examine paired samples (also called matched pairs or dependent samples).
10.8.1 Why Use Paired Samples?
Key Advantage: Pairing reduces variability by controlling for differences between subjects.
Example: Testing a training program’s effectiveness - Independent samples approach: Compare Group A (trained) vs. Group B (untrained) - Problem: Groups may differ in experience, education, motivation - Result: High variability masks training effect
- Paired samples approach: Measure each person before AND after training
- Benefit: Each person serves as their own control
- Result: Lower variability, more powerful test
10.8.2 The Paired Difference Approach
Instead of analyzing two separate samples, we analyze one sample of differences.
ImportantKey Transformation: Two Samples → One Sample
For each pair (X_{1i}, X_{2i}), calculate the difference:
d_i = X_{1i} - X_{2i}
Then analyze the differences using single-sample methods!
- Sample mean of differences: \bar{d} = \frac{\sum d_i}{n}
- Sample standard deviation: s_d = \sqrt{\frac{\sum d_i^2 - n\bar{d}^2}{n-1}}
- Sample size: n = number of pairs
10.8.3 Confidence Interval for Paired Differences
10.8.4 Example: Employee Training Program Effectiveness
Scenario: Management Development Assessment
A company instituted a training program to improve employee performance scores. To evaluate effectiveness, 10 employees were scored before and after training.
Sample Data:
| Employee | Before Training | After Training | Difference (d) |
|---|---|---|---|
| 1 | 72 | 78 | -6 |
| 2 | 65 | 71 | -6 |
| 3 | 83 | 89 | -6 |
| 4 | 91 | 93 | -2 |
| 5 | 58 | 68 | -10 |
| 6 | 77 | 82 | -5 |
| 7 | 69 | 75 | -6 |
| 8 | 74 | 79 | -5 |
| 9 | 88 | 91 | -3 |
| 10 | 81 | 86 | -5 |
Note: d_i = \text{Before} - \text{After} (negative values indicate improvement)
Objective: Construct a 95% confidence interval for the mean improvement.
Solution:
Step 1: Calculate Mean Difference
\bar{d} = \frac{\sum d_i}{n} = \frac{-54}{10} = -5.4
Step 2: Calculate Standard Deviation
First, find \sum d_i^2: \sum d_i^2 = (-6)^2 + (-6)^2 + (-6)^2 + (-2)^2 + (-10)^2 + (-5)^2 + (-6)^2 + (-5)^2 + (-3)^2 + (-5)^2 = 36 + 36 + 36 + 4 + 100 + 25 + 36 + 25 + 9 + 25 = 332
Then: s_d = \sqrt{\frac{\sum d_i^2 - n\bar{d}^2}{n-1}} = \sqrt{\frac{332 - 10(-5.4)^2}{9}} = \sqrt{\frac{332 - 291.6}{9}} = \sqrt{\frac{40.4}{9}} = \sqrt{4.489} = 2.12
Step 3: Find Critical t-Value
- 95% confidence level
- df = n - 1 = 10 - 1 = 9
- From t-table: t_{0.025, 9} = 2.262
Step 4: Calculate Confidence Interval
\text{C.I.} = \bar{d} \pm t \frac{s_d}{\sqrt{n}} = -5.4 \pm 2.262 \times \frac{2.12}{\sqrt{10}} = -5.4 \pm 2.262 \times 0.671 = -5.4 \pm 1.52 -6.92 \leq (\mu_{\text{before}} - \mu_{\text{after}}) \leq -3.88
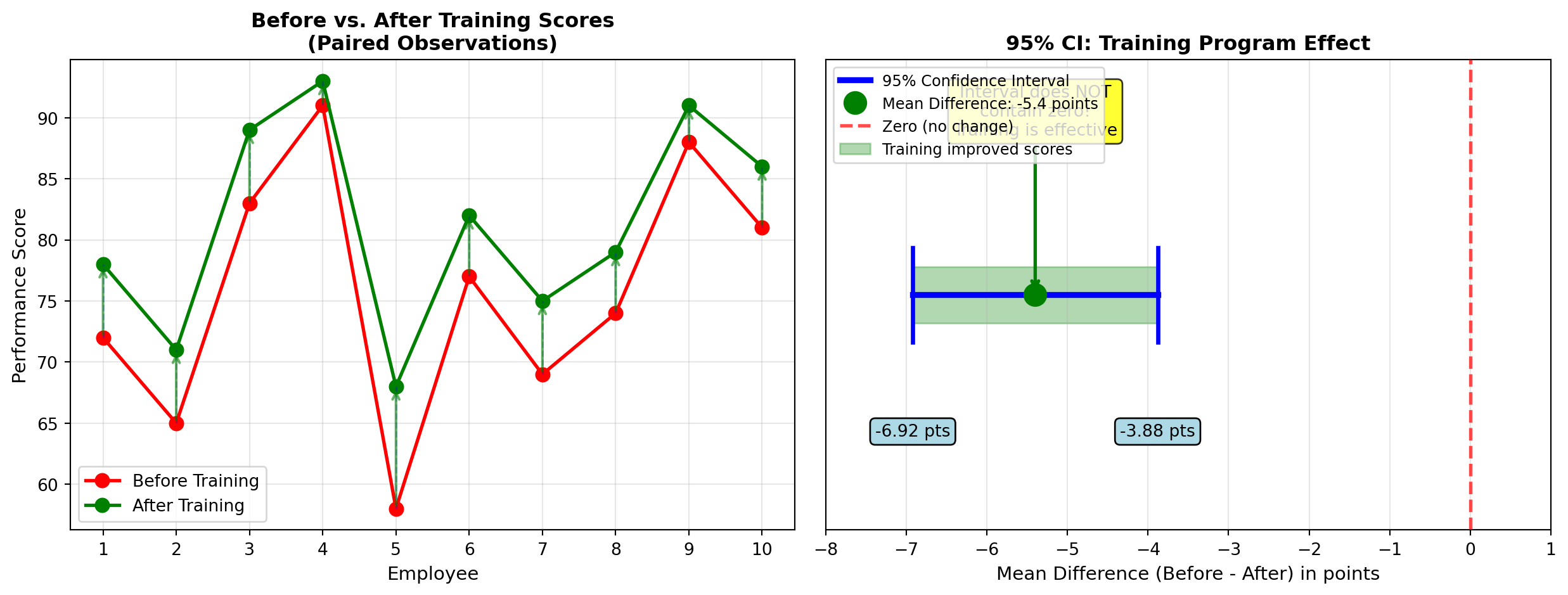
Interpretation:
Converting to positive values (After - Before), we can be 95% confident that training improves average performance by 3.88 to 6.92 points.
ImportantBusiness Conclusion: Training Is Effective
The interval does not contain zero, providing strong evidence that training genuinely improves employee performance. The company should continue the program.
Estimated ROI: With average improvement of 5.4 points, management can justify training investment based on productivity gains.
10.8.5 Example 9.4: Hospital Billing Comparison (Vicki Peplow)
Scenario: Healthcare Cost Analysis
Vicki Peplow works for a large corporation that self-insures medical costs. The company has negotiated contracts with two hospitals. Vicki wants to determine if there’s a difference in average costs between the hospitals for identical procedures.
Strategy: Use paired samples by matching the same procedures at both hospitals.
Sample Data: 15 common procedures
| Procedure | Hospital 1 Cost | Hospital 2 Cost | Difference (d) |
|---|---|---|---|
| Appendectomy | $4,250 | $4,180 | $70 |
| Cholecystectomy | $6,780 | $6,920 | -$140 |
| Hernia repair | $3,450 | $3,610 | -$160 |
| Hysterectomy | $7,200 | $7,050 | $150 |
| Knee arthroscopy | $5,100 | $5,280 | -$180 |
| Cataract surgery | $2,800 | $2,650 | $150 |
| Tonsillectomy | $1,950 | $2,100 | -$150 |
| Colonoscopy | $1,680 | $1,720 | -$40 |
| Hip replacement | $18,500 | $18,700 | -$200 |
| Angioplasty | $12,300 | $12,150 | $150 |
| Mastectomy | $8,900 | $9,200 | -$300 |
| Spinal fusion | $22,100 | $22,350 | -$250 |
| Cesarean section | $6,400 | $6,300 | $100 |
| Cardiac bypass | $35,200 | $35,100 | $100 |
| Total knee | $24,500 | $24,800 | -$300 |
Calculations:
\sum d_i = -884 \sum d_i^2 = 400,716
Objective: Construct a 95% confidence interval for the difference in average costs.
Solution:
Step 1: Calculate Mean Difference
\bar{d} = \frac{\sum d_i}{n} = \frac{-884}{15} = -58.93
Step 2: Calculate Standard Deviation
s_d = \sqrt{\frac{\sum d_i^2 - n\bar{d}^2}{n-1}} = \sqrt{\frac{400,716 - 15(-58.93)^2}{14}} = \sqrt{\frac{400,716 - 52,099}{14}} = \sqrt{\frac{348,617}{14}} = \sqrt{24,901.2} = 157.8
Step 3: Find Critical t-Value
- 95% confidence level
- df = 15 - 1 = 14
- From t-table: t_{0.025, 14} = 2.145
Step 4: Calculate Confidence Interval
\text{C.I.} = \bar{d} \pm t \frac{s_d}{\sqrt{n}} = -58.93 \pm 2.145 \times \frac{157.8}{\sqrt{15}} = -58.93 \pm 2.145 \times 40.76 = -58.93 \pm 87.4 -146.33 \leq (\mu_1 - \mu_2) \leq 28.47
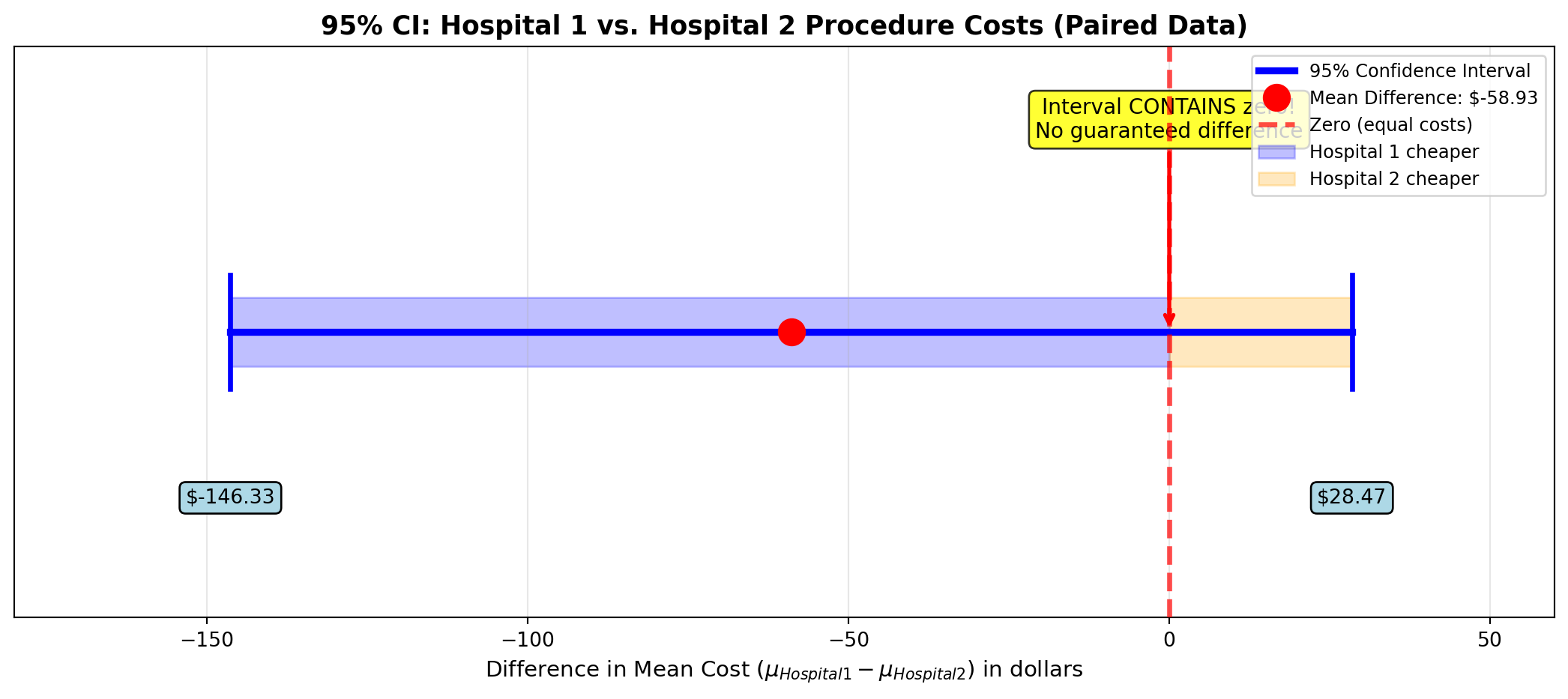
Interpretation:
We can be 95% confident that the difference in average costs is between: - $146.33 less at Hospital 1, OR - $28.47 less at Hospital 2
10.9 9.4 Confidence Intervals for Two Proportions
Many business decisions require comparing proportions from two populations: - Defect rates from two production processes - Customer satisfaction rates across product versions - Default rates between loan portfolios - Click-through rates for two ad campaigns
10.9.1 Point Estimate for Difference
The point estimate for the difference between population proportions is:
\text{Point estimate: } p_1 - p_2
Where p_1 and p_2 are the sample proportions.
10.9.2 Standard Error of the Difference
10.9.3 Confidence Interval Formula
ImportantC.I. for (\pi_1 - \pi_2)
\text{C.I. for } (\pi_1 - \pi_2) = (p_1 - p_2) \pm Z \cdot s_{p_1-p_2}
Where: - p_1, p_2 = sample proportions - Z = critical Z-value for desired confidence level - s_{p_1-p_2} = standard error of the difference
10.9.4 Example: Worker Absenteeism Study
Scenario: Human Resources Analysis
A large manufacturing company suspects that night shift workers have higher absenteeism rates than day shift workers. HR collects data from both shifts.
Sample Data:
| Shift | Sample Size | Number Absent | Sample Proportion |
|---|---|---|---|
| Night shift | n₁ = 150 | 22 | p₁ = 0.147 |
| Day shift | n₂ = 150 | 14 | p₂ = 0.093 |
Objective: Construct a 90% confidence interval for the difference in absenteeism rates.
Solution:
Step 1: Verify Sample Size Requirements
- Night shift: n_1 p_1 = 150(0.147) = 22 \geq 5 ✓ and n_1(1-p_1) = 150(0.853) = 128 \geq 5 ✓
- Day shift: n_2 p_2 = 150(0.093) = 14 \geq 5 ✓ and n_2(1-p_2) = 150(0.907) = 136 \geq 5 ✓
Step 2: Calculate Standard Error
s_{p_1-p_2} = \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}} = \sqrt{\frac{0.147(0.853)}{150} + \frac{0.093(0.907)}{150}} = \sqrt{\frac{0.1254}{150} + \frac{0.0844}{150}} = \sqrt{0.000836 + 0.000563} = \sqrt{0.001399} = 0.0374
Step 3: Find Critical Z-Value
- 90% confidence level → α = 0.10
- Z_{0.05} = 1.645
Step 4: Calculate Confidence Interval
\text{C.I.} = (p_1 - p_2) \pm Z \cdot s_{p_1-p_2} = (0.147 - 0.093) \pm 1.645(0.0374) = 0.054 \pm 0.0615 -0.0075 \leq (\pi_1 - \pi_2) \leq 0.1155
Or: -0.75% ≤ (π₁ - π₂) ≤ 11.55%
Interpretation:
Because the interval contains zero (-0.75% to +11.55%), we cannot conclusively state that night shift absenteeism is higher at the 90% confidence level.
HR Recommendation: While the data suggests night shift may have up to 11.55% higher absenteeism, the difference could also be as low as -0.75% (day shift slightly higher). More data would be needed for a definitive conclusion.
10.9.5 Example 9.5: Ice Capades Costume Defects
Scenario: Quality Control for Entertainment Production
Ice Capades produces elaborate costumes using two manufacturing methods. Quality control inspects costumes for defects.
Sample Data:
| Method | Costumes Inspected | Defective | Defect Rate |
|---|---|---|---|
| Method A | n₁ = 200 | 42 | p₁ = 0.21 |
| Method B | n₂ = 250 | 65 | p₂ = 0.26 |
Objective: Construct a 95% confidence interval for the difference in defect rates.
Solution:
Step 1: Calculate Standard Error
s_{p_1-p_2} = \sqrt{\frac{0.21(0.79)}{200} + \frac{0.26(0.74)}{250}} = \sqrt{\frac{0.1659}{200} + \frac{0.1924}{250}} = \sqrt{0.0008295 + 0.0007696} = \sqrt{0.0015991} = 0.04
Step 2: Find Critical Z-Value
- 95% confidence level
- Z_{0.025} = 1.96
Step 3: Calculate Confidence Interval
\text{C.I.} = (0.21 - 0.26) \pm 1.96(0.04) = -0.05 \pm 0.0784 -0.1284 \leq (\pi_A - \pi_B) \leq 0.0284
Or: -12.84% ≤ (π_A - π_B) ≤ 2.84%
Interpretation:
Method A could have a defect rate that is: - As much as 12.84% lower than Method B (Method A better), OR - As much as 2.84% higher than Method B (Method B better)
TipBusiness Decision: Methods Appear Equivalent
The interval contains zero, suggesting no statistically significant difference at 95% confidence. Ice Capades can choose either method based on cost, production speed, or other non-quality factors.
If Method A is less expensive, use Method A. If Method B is faster, use Method B. Quality differences are not proven.
10.10 9.5 Sample Size Determination for Two-Population Studies
When planning a study comparing two populations, researchers must determine adequate sample sizes.
10.10.1 For Comparing Two Means
Example: Estimate the difference in average customer wait times between two service centers within ±2 minutes at 95% confidence. From pilot data: \sigma_1 = 8 minutes, \sigma_2 = 10 minutes.
n = \frac{(1.96)^2(64 + 100)}{(2)^2} = \frac{3.8416(164)}{4} = \frac{630.02}{4} = 157.5
Required sample size: n = 158 customers from each center.
10.10.2 For Comparing Two Proportions
Example: Estimate the difference in customer satisfaction rates between two product versions within ±5% at 99% confidence. No prior data available.
n = \frac{0.5(2.576)^2}{(0.05)^2} = \frac{0.5(6.636)}{0.0025} = \frac{3.318}{0.0025} = 1,327.2
Required sample size: n = 1,328 customers per product version.
10.11 Section Exercises: Paired Samples and Proportions
13. Paired Data Interpretation: A confidence interval for paired data yields: -12.5 \leq (\mu_1 - \mu_2) \leq 5.3. What can you conclude about the relationship between the two population means?
14. Magazine Subscription Prices: A consumer group wants to compare subscription prices between two magazines available at newsstands and through mail subscriptions. They sample 8 magazines:
| Magazine | Newsstand | Difference | |
|---|---|---|---|
| Time | $4.95 | $3.50 | $1.45 |
| Newsweek | $4.50 | $3.25 | $1.25 |
| Fortune | $5.95 | $4.75 | $1.20 |
| Sports Illustrated | $3.95 | $2.95 | $1.00 |
| Vogue | $4.25 | $3.50 | $0.75 |
| Business Week | $5.50 | $4.50 | $1.00 |
| The Economist | $6.95 | $5.95 | $1.00 |
| National Geographic | $3.50 | $2.75 | $0.75 |
Construct a 90% confidence interval for the average price difference.
15. Diet Program Effectiveness: A weight-loss clinic measures 12 clients before and after a 6-week program:
Before (lbs): 185, 220, 198, 175, 210, 195, 188, 203, 225, 192, 178, 207
After (lbs): 178, 210, 192, 170, 201, 189, 183, 196, 215, 186, 175, 200
Calculate a 95% confidence interval for the mean weight loss.
16. Department Store Credit Usage: Two samples of credit customers show: - Downtown store: 120 customers, 69 used credit (p₁ = 0.575) - Suburban store: 150 customers, 73 used credit (p₂ = 0.487)
Construct a 99% confidence interval for the difference in credit usage rates.
17. Manufacturing Defect Rates: Process A produces 500 units with 28 defects. Process B produces 700 units with 31 defects. Find a 90% confidence interval for the difference in defect rates.
18. Sample Size for Salary Comparison: A consultant wants to estimate the difference in average salaries between two regions within ±$5,000 at 95% confidence. Pilot data suggests \sigma_1 = \$18,000 and \sigma_2 = \$22,000. What sample size is needed?
19. Sample Size for Market Share: A company wants to estimate the difference in market share between two products within ±3% at 99% confidence. No prior data exists. What sample size is required?
20. Advertising Effectiveness (Paired): A retailer measures daily sales for 7 days before and after an advertising campaign:
Before: $12,500, $11,800, $13,200, $12,100, $11,900, $12,700, $13,500
After: $13,800, $12,900, $14,100, $13,200, $12,800, $13,900, $14,700
Does a 95% confidence interval suggest the campaign increased sales?
21. Employee Turnover Rates: Company A (n=300) had 42 employees leave last year. Company B (n=250) had 28 employees leave. Construct a 95% confidence interval for the difference in turnover rates and interpret the business implications.
End of Stage 3
This completes the third stage covering: - Paired samples (matched pairs) methodology - Why pairing reduces variability - Confidence intervals for paired differences - Employee training example - Hospital billing comparison (Example 9.4) - Confidence intervals for two proportions - Standard error for difference in proportions - Worker absenteeism study - Ice Capades costume defects (Example 9.5) - Sample size determination for means and proportions - 9 comprehensive section exercises
Coming in Stage 4: - Hypothesis testing for two means (independent samples) - Hypothesis testing for paired samples - Hypothesis testing for two proportions - Golf course playing times example - Johnson Manufacturing defect rates - Complete examples with business interpretations # Two-Population Inferences - Stage 4
10.12 9.6 Hypothesis Testing for Two Population Means
In previous sections, we focused on interval estimation—constructing confidence intervals to estimate the difference between population means. Now we turn to hypothesis testing—making decisions about whether a claimed difference exists.
10.12.1 General Framework for Hypothesis Tests
The test statistic structure mirrors the confidence interval approach:
\text{Test Statistic} = \frac{(\text{Sample Difference}) - (\text{Hypothesized Difference})}{\text{Standard Error}}
Common null hypothesis: H_0: \mu_1 = \mu_2 (equivalent to \mu_1 - \mu_2 = 0)
Alternative hypotheses (three possibilities):
- Two-tailed: H_A: \mu_1 \neq \mu_2 (difference exists, direction unknown)
- Right-tailed: H_A: \mu_1 > \mu_2 (first population mean is greater)
- Left-tailed: H_A: \mu_1 < \mu_2 (first population mean is smaller)
10.13 A. Hypothesis Tests with Large Samples
When both samples are large (n₁ ≥ 30 and n₂ ≥ 30), we use the Z-test.
ImportantZ-Test for Two Means (Large Samples)
Z = \frac{(\bar{X}_1 - \bar{X}_2) - (\mu_1 - \mu_2)}{s_{\bar{X}_1 - \bar{X}_2}}
Where: s_{\bar{X}_1 - \bar{X}_2} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}
Decision Rule: - Two-tailed: Reject H₀ if |Z| > Z_{α/2} - Right-tailed: Reject H₀ if Z > Z_α - Left-tailed: Reject H₀ if Z < -Z_α
10.13.1 Example: Golf Course Playing Times (Men vs. Women)
Scenario: Course Management Resource Allocation
The manager of Pine Valley Golf Course wants to determine if there’s a difference in average playing times between men and women. This information will help schedule tee times and allocate course resources.
Sample Data:
| Group | Sample Size | Mean Time | Std Dev |
|---|---|---|---|
| Men | n_m = 100 | \bar{X}_m = 4.2 hrs | s_m = 0.8 hrs |
| Women | n_w = 75 | \bar{X}_w = 4.7 hrs | s_w = 0.6 hrs |
Hypotheses:
H_0: \mu_m = \mu_w \quad \text{(no difference in average playing times)} H_A: \mu_m \neq \mu_w \quad \text{(playing times differ)}
Significance Level: α = 0.01 (1%)
Solution:
Step 1: Calculate Standard Error
s_{\bar{X}_m - \bar{X}_w} = \sqrt{\frac{s_m^2}{n_m} + \frac{s_w^2}{n_w}} = \sqrt{\frac{(0.8)^2}{100} + \frac{(0.6)^2}{75}} = \sqrt{\frac{0.64}{100} + \frac{0.36}{75}} = \sqrt{0.0064 + 0.0048} = \sqrt{0.0112} = 0.106
Step 2: Calculate Test Statistic
Z = \frac{(\bar{X}_m - \bar{X}_w) - 0}{s_{\bar{X}_m - \bar{X}_w}} = \frac{(4.2 - 4.7) - 0}{0.106} = \frac{-0.5}{0.106} = -4.72
Step 3: Determine Critical Values and Decision Rule
For α = 0.01 (two-tailed test): - Critical values: Z_{0.005} = \pm 2.576
Decision Rule: “Reject H₀ if Z < -2.576 or Z > +2.576”
Step 4: Make Decision
Z = -4.72 < -2.576 → Reject H₀
Step 5: Calculate p-value
For Z = -4.72: - Area in left tail ≈ 0.000001 - p-value = 2(0.000001) ≈ 0.000002 (two-tailed)
C:\Users\patod\AppData\Local\Temp\ipykernel_15512\2446534838.py:43: MatplotlibDeprecationWarning: The 'labels' parameter of boxplot() has been renamed 'tick_labels' since Matplotlib 3.9; support for the old name will be dropped in 3.11.
bp = ax2.boxplot([men_times, women_times],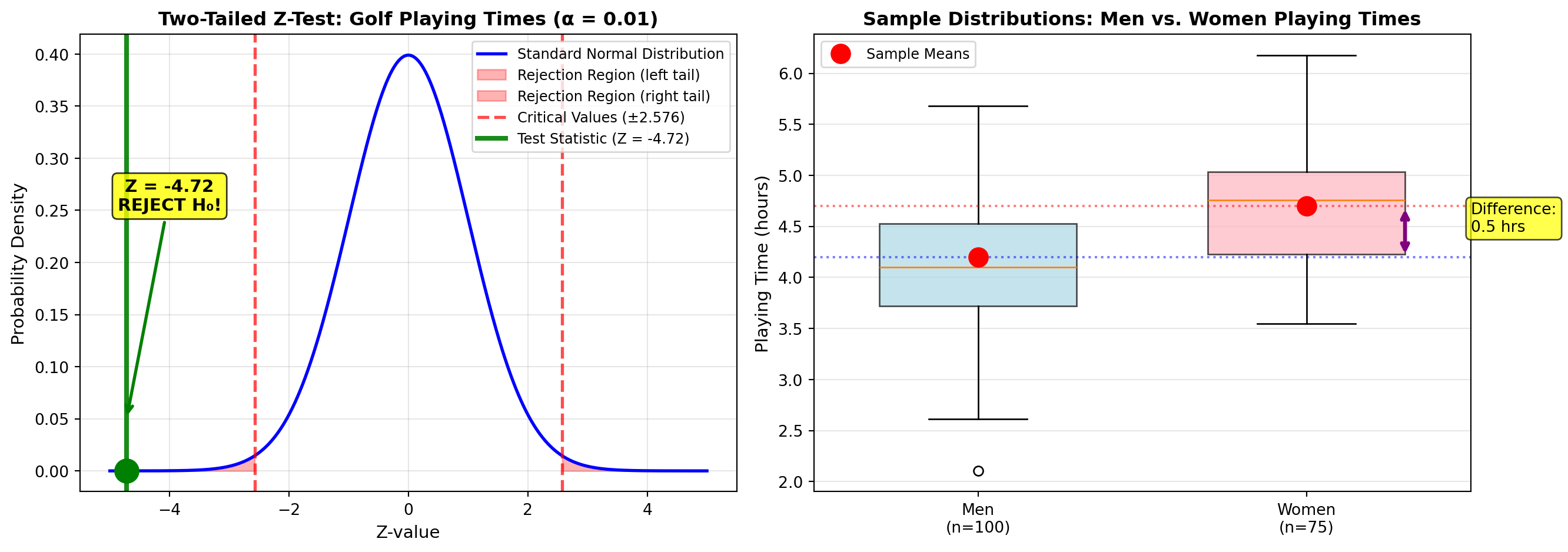
Interpretation:
ImportantBusiness Conclusion: Significant Difference Exists
Statistical Finding: At α = 0.01, there’s strong evidence that average playing times differ between men and women. The p-value ≈ 0.000002 indicates this result is extremely unlikely to occur by chance.
Practical Finding: Women take an average of 0.5 hours (30 minutes) longer to complete a round.
Management Recommendations: 1. Tee time scheduling: Build in 30-minute buffers when women’s groups follow men’s groups 2. Course pacing: Post different pace-of-play guidelines for different groups 3. Resource allocation: Consider dedicated tee times for women’s leagues 4. Revenue optimization: Adjust pricing to account for longer course occupation times
Important Note: This finding reflects averages and should not influence individual golfer policies. Many women play faster than many men.
10.13.2 Alternative Hypothesis Formulation: One-Tailed Test
Suppose the golf course manager had a directional hypothesis—specifically suspecting that women take longer than men.
Revised Hypotheses:
H_0: \mu_w \leq \mu_m \quad \text{(women don't take longer)} H_A: \mu_w > \mu_m \quad \text{(women take longer)}
Equivalently (subtracting in opposite order):
H_0: \mu_m \geq \mu_w H_A: \mu_m < \mu_w
Solution for One-Tailed Test:
The test statistic remains: Z = -4.72
New Decision Rule (left-tailed test, α = 0.01): - Critical value: Z_{0.01} = -2.33 - Decision Rule: “Reject H₀ if Z < -2.33”
Decision: Z = -4.72 < -2.33 → Reject H₀
p-value (one-tailed): ≈ 0.000001
Conclusion: Same result—strong evidence that women take longer than men. The one-tailed test provides even stronger evidence (smaller p-value) because all α is concentrated in one tail.
10.14 B. Hypothesis Tests with Small Samples: The t-Distribution
When either sample is small (n < 30), we must use the t-distribution instead of the Z-distribution.
10.14.1 1. Equal Variances: Pooled t-Test
When population variances are equal (\sigma_1^2 = \sigma_2^2):
ImportantPooled t-Test for Two Means (Small Samples, Equal Variances)
t = \frac{(\bar{X}_1 - \bar{X}_2) - (\mu_1 - \mu_2)}{\sqrt{s_p^2\left(\frac{1}{n_1} + \frac{1}{n_2}\right)}}
Where: s_p^2 = \frac{s_1^2(n_1-1) + s_2^2(n_2-1)}{n_1 + n_2 - 2}
Degrees of freedom: df = n_1 + n_2 - 2
10.14.2 Example: Revisiting Charles Schwab Training (from Example 9.1)
Context: In Example 9.1, we constructed a 99% confidence interval for the difference in competency levels between two employee training programs. The result was:
-8.34 \leq (\mu_1 - \mu_2) \leq 4.40
What if we wanted to TEST the hypothesis that the programs produce equal competency levels?
Sample Data (from Example 9.1):
| Program | Sample Size | Mean Score | Std Dev |
|---|---|---|---|
| Program 1 | n₁ = 45 | \bar{X}_1 = 76.0 | s₁ = 13.5 |
| Program 2 | n₂ = 40 | \bar{X}_2 = 77.97 | s₂ = 9.05 |
Hypotheses:
H_0: \mu_1 = \mu_2 \quad \text{(programs equally effective)} H_A: \mu_1 \neq \mu_2 \quad \text{(programs differ in effectiveness)}
Significance Level: α = 0.01
Solution:
Given the data from Example 9.1, the standard error was calculated as:
s_{\bar{X}_1 - \bar{X}_2} = 2.47
Step 1: Calculate Test Statistic
Z = \frac{(\bar{X}_1 - \bar{X}_2) - 0}{s_{\bar{X}_1 - \bar{X}_2}} = \frac{(76.0 - 77.97) - 0}{2.47} = \frac{-1.97}{2.47} = -0.79
Step 2: Critical Values and Decision Rule
For α = 0.01 (two-tailed): - Critical values: Z_{0.005} = \pm 2.58
Decision Rule: “Reject H₀ if |Z| > 2.58”
Step 3: Make Decision
|Z| = |-0.79| = 0.79 < 2.58 → Do NOT Reject H₀
Step 4: Calculate p-value
For Z = -0.79: - Area in left tail = 0.5 - 0.2852 = 0.2148 - p-value = 2(0.2148) = 0.4296
Interpretation:
10.14.3 Example 9.6: Labor Negotiations Revisited (from Example 9.2)
In Example 9.2, we constructed a 98% confidence interval for wage differences between Atlanta and Newport News plants:
-5.09 \leq (\mu_A - \mu_N) \leq 9.15
Now test the hypothesis of equal wages.
Sample Data (from Example 9.2):
| Plant | Sample Size | Mean Wage | Variance |
|---|---|---|---|
| Atlanta | n_A = 23 | \bar{X}_A = \$17.53/hr | s_A^2 = 92.10 |
| Newport News | n_N = 19 | \bar{X}_N = \$15.50/hr | s_N^2 = 87.10 |
From Example 9.2: Pooled variance s_p^2 = 89.85
Hypotheses:
H_0: \mu_A = \mu_N H_A: \mu_A \neq \mu_N
Significance Level: α = 0.02
Solution:
Step 1: Calculate Test Statistic
t = \frac{(17.53 - 15.50) - 0}{\sqrt{89.85\left(\frac{1}{23} + \frac{1}{19}\right)}} = \frac{2.03}{\sqrt{89.85(0.0435 + 0.0526)}} = \frac{2.03}{\sqrt{89.85 \times 0.0961}} = \frac{2.03}{\sqrt{8.635}} = \frac{2.03}{2.939} = 0.69
Step 2: Critical Values and Decision Rule
- df = 23 + 19 - 2 = 40
- α = 0.02 (two-tailed)
- From t-table: t_{0.01, 40} = \pm 2.423
Decision Rule: “Reject H₀ if |t| > 2.423”
Step 3: Make Decision
|t| = 0.69 < 2.423 → Do NOT Reject H₀
Interpretation:
No evidence of wage difference between plants. This confirms the confidence interval result (which contained zero). The labor negotiator can assure both sides that wages are statistically equivalent.
10.14.4 2. Unequal Variances: Separate Variance t-Test
When variances are unequal (\sigma_1^2 \neq \sigma_2^2):
ImportantSeparate Variance t-Test (Unequal Variances)
t' = \frac{(\bar{X}_1 - \bar{X}_2) - (\mu_1 - \mu_2)}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}
Adjusted degrees of freedom: df = \frac{\left(\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}\right)^2}{\frac{(s_1^2/n_1)^2}{n_1-1} + \frac{(s_2^2/n_2)^2}{n_2-1}}
10.14.5 Example: Acme Shock Absorbers Revisited (from Example 9.3)
In Example 9.3, we found a 98% confidence interval:
0.5 \leq (\mu_1 - \mu_2) \leq 7.1 \text{ weeks}
Test whether Type 1 shock absorbers are more durable than Type 2.
Sample Data (from Example 9.3):
| Type | Sample Size | Mean Duration | Std Dev |
|---|---|---|---|
| Type 1 | n₁ = 13 | \bar{X}_1 = 11.3 wks | s₁ = 3.5 wks |
| Type 2 | n₂ = 10 | \bar{X}_2 = 7.5 wks | s₂ = 2.7 wks |
Hypotheses:
H_0: \mu_1 = \mu_2 H_A: \mu_1 \neq \mu_2
Significance Level: α = 0.02
Solution:
From Example 9.3: Adjusted df = 20
Step 1: Calculate Test Statistic
t' = \frac{(11.3 - 7.5) - 0}{\sqrt{\frac{(3.5)^2}{13} + \frac{(2.7)^2}{10}}} = \frac{3.8}{\sqrt{0.942 + 0.729}} = \frac{3.8}{1.293} = 2.94
Step 2: Critical Values
- df = 20, α = 0.02 (two-tailed)
- From t-table: t'_{0.01, 20} = \pm 2.528
Decision Rule: “Reject H₀ if |t’| > 2.528”
Step 3: Make Decision
|t’| = 2.94 > 2.528 → Reject H₀
Interpretation:
ImportantStatistical Finding: Type 1 IS More Durable
At α = 0.02, there’s significant evidence that Type 1 shock absorbers last longer than Type 2.
However, recall from Example 9.3: The CEO requires at least 8 weeks additional durability to justify Type 1’s higher cost. The confidence interval (0.5 to 7.1 weeks) shows the true difference is likely less than 8 weeks.
Business Decision: Despite statistical significance, Type 1 does not meet the business requirement. Continue using Type 2 (less expensive option).
Key Lesson: Statistical significance ≠ Practical significance!
10.15 9.7 Hypothesis Testing for Paired Samples
Paired samples hypothesis testing follows the same logic as paired confidence intervals—analyze the differences as a single sample.
Importantt-Test for Paired Samples
t = \frac{\bar{d} - (\mu_1 - \mu_2)}{\frac{s_d}{\sqrt{n}}}
Where: - \bar{d} = mean of paired differences - s_d = standard deviation of differences - n = number of pairs - df = n - 1
For testing equality: H_0: \mu_1 = \mu_2 becomes H_0: \mu_d = 0
10.15.1 Example: Hospital Billing Revisited (from Example 9.4)
In Example 9.4, Vicki Peplow constructed a 95% confidence interval for hospital cost differences:
-\$146.33 \leq (\mu_1 - \mu_2) \leq \$28.47
Test the hypothesis of equal average costs.
Sample Data (from Example 9.4): - n = 15 paired procedures - \sum d_i = -884 - \sum d_i^2 = 400,716
From Example 9.4 calculations: - \bar{d} = -58.93 - s_d = 157.8
Hypotheses:
H_0: \mu_1 = \mu_2 \quad \text{(equal costs)} H_A: \mu_1 \neq \mu_2 \quad \text{(costs differ)}
Significance Level: α = 0.05
Solution:
Step 1: Calculate Test Statistic
t = \frac{\bar{d} - 0}{\frac{s_d}{\sqrt{n}}} = \frac{-58.93}{\frac{157.8}{\sqrt{15}}} = \frac{-58.93}{40.76} = -1.44
Step 2: Critical Values
- df = 15 - 1 = 14
- α = 0.05 (two-tailed)
- From t-table: t_{0.025, 14} = \pm 2.145
Decision Rule: “Reject H₀ if |t| > 2.145”
Step 3: Make Decision
|t| = 1.44 < 2.145 → Do NOT Reject H₀
Interpretation:
No evidence of cost difference between hospitals. This confirms the confidence interval result (which contained zero). Vicki reports that both hospitals appear equivalent for cost purposes.
10.16 9.8 Hypothesis Testing for Two Proportions
Business problems frequently require comparing proportions between two populations: - Defect rates from two production methods - Default rates between loan portfolios
- Customer satisfaction between product versions - Response rates to different marketing campaigns
ImportantZ-Test for Difference Between Two Proportions
Z = \frac{(p_1 - p_2) - (\pi_1 - \pi_2)}{s_{p_1 - p_2}}
Where: s_{p_1-p_2} = \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}
Requirements: - n_1p_1 \geq 5, n_1(1-p_1) \geq 5 - n_2p_2 \geq 5, n_2(1-p_2) \geq 5
10.16.1 Example: Retail Credit Usage by Gender
Scenario: Credit Department Analysis
A retail store wants to test whether the proportion of male customers who use credit equals the proportion of female customers who use credit.
Sample Data:
| Gender | Sample Size | Used Credit | Proportion |
|---|---|---|---|
| Men | n_m = 100 | 57 | p_m = 0.57 |
| Women | n_w = 110 | 52 | p_w = 0.473 |
Hypotheses:
H_0: \pi_m = \pi_w H_A: \pi_m \neq \pi_w
Significance Level: α = 0.01
Solution:
Step 1: Verify Requirements
- Men: 100(0.57) = 57 \geq 5 ✓ and 100(0.43) = 43 \geq 5 ✓
- Women: 110(0.473) = 52 \geq 5 ✓ and 110(0.527) = 58 \geq 5 ✓
Step 2: Calculate Standard Error
s_{p_m - p_w} = \sqrt{\frac{0.57(0.43)}{100} + \frac{0.473(0.527)}{110}} = \sqrt{\frac{0.2451}{100} + \frac{0.2493}{110}} = \sqrt{0.002451 + 0.002266} = \sqrt{0.004717} = 0.069
Step 3: Calculate Test Statistic
Z = \frac{(0.57 - 0.473) - 0}{0.069} = \frac{0.097}{0.069} = 1.41
Step 4: Critical Values and Decision Rule
For α = 0.01 (two-tailed): - Critical values: Z_{0.005} = \pm 2.58
Decision Rule: “Reject H₀ if |Z| > 2.58”
Step 5: Make Decision
|Z| = 1.41 < 2.58 → Do NOT Reject H₀
Interpretation:
At α = 0.01, there’s no evidence that credit usage proportions differ between men and women. The store should not implement gender-specific credit marketing strategies.
10.16.2 Example 9.7: Johnson Manufacturing Defect Rates
Scenario: Quality Control for Shift Performance
Johnson Manufacturing has experienced increased defect rates. The production supervisor suspects the night shift produces a higher proportion of defects than the day shift.
Sample Data:
| Shift | Units Inspected | Defects | Defect Rate |
|---|---|---|---|
| Day shift | n_D = 500 | 14 | p_D = 0.028 |
| Night shift | n_N = 700 | 22 | p_N = 0.031 |
Decision Context: If night shift defect rate is significantly higher, institute a training program for night workers.
Hypotheses:
H_0: \pi_N \leq \pi_D \quad \text{(night shift not worse)} H_A: \pi_N > \pi_D \quad \text{(night shift has higher defects)}
Significance Level: α = 0.05
Solution:
Step 1: Calculate Standard Error
s_{p_N - p_D} = \sqrt{\frac{0.031(0.969)}{700} + \frac{0.028(0.972)}{500}} = \sqrt{\frac{0.0300}{700} + \frac{0.0272}{500}} = \sqrt{0.0000429 + 0.0000544} = \sqrt{0.0000973} = 0.0099
Step 2: Calculate Test Statistic
Z = \frac{(0.031 - 0.028) - 0}{0.0099} = \frac{0.003}{0.0099} = 0.303
Step 3: Critical Value (Right-Tailed Test)
For α = 0.05 (right-tailed): - Critical value: Z_{0.05} = 1.65
Decision Rule: “Reject H₀ if Z > 1.65”
Step 4: Make Decision
Z = 0.303 < 1.65 → Do NOT Reject H₀
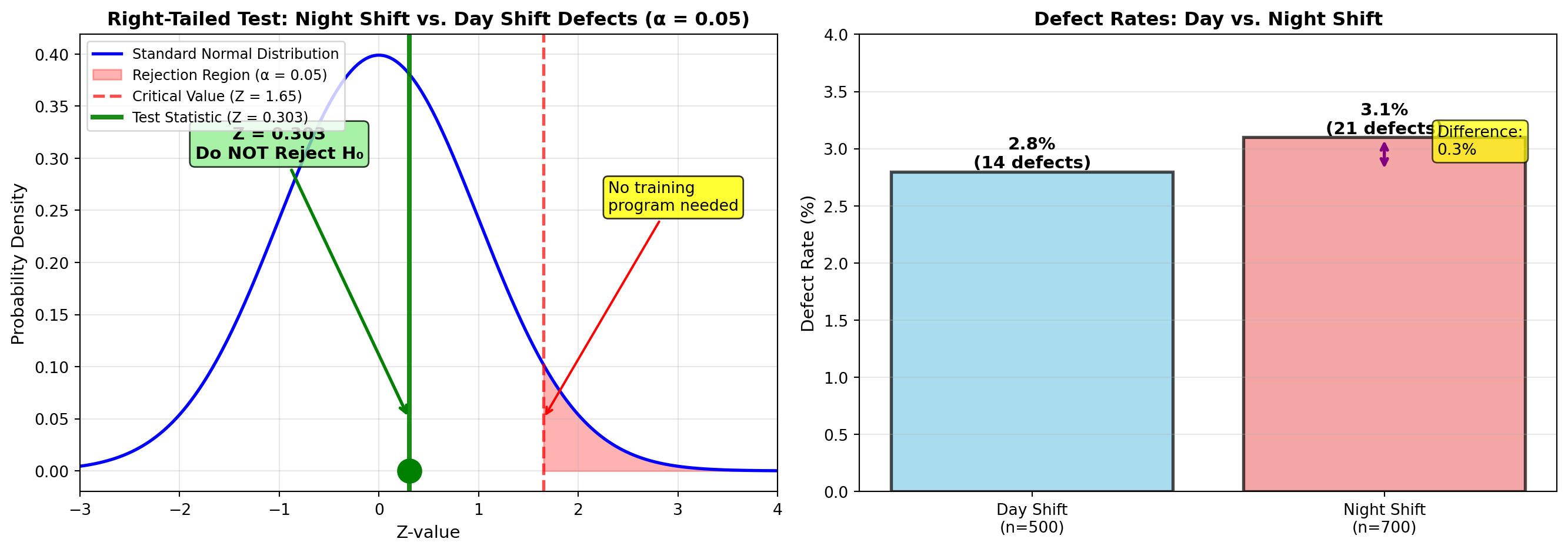
Interpretation:
ImportantBusiness Decision: Do NOT Institute Training Program
Statistical Finding: At α = 0.05, there’s insufficient evidence to conclude that night shift workers produce a higher defect rate than day shift workers.
The observed difference (3.1% vs. 2.8%) could easily be due to random variation rather than a systematic problem with night shift performance.
Supervisor’s Recommendation: - Do not implement the training program (saves training costs) - Continue monitoring defect rates over time - Investigate other factors if defects remain elevated (equipment maintenance, raw material quality, environmental conditions)
Cost-Benefit Note: Training program avoided. If defects were truly a night shift issue, the test would have detected it with these sample sizes.
10.17 Section Exercises: Hypothesis Testing
22. Samples of sizes 50 and 60 reveal means of 512 and 587, and standard deviations of 125 and 145 respectively. At α = 0.02, test the hypothesis that μ₁ = μ₂.
23. At α = 0.01, test equality of means if samples of size 10 and 8 give means of 36 and 49, and standard deviations of 12 and 18, respectively. Assume variances are NOT equal.
24. Repeat problem 23 assuming variances ARE equal.
25. Paired samples of size 81 give a mean difference of 36.5 and a standard deviation of differences of 29.1. Test equality of means at α = 0.01.
26. Test H_0: \mu_1 \leq \mu_2 if samples of sizes 64 and 81 produce means of 65.2 and 58.6, and standard deviations of 21.2 and 25.3. Use α = 0.05.
27. Test H_0: \mu_1 \geq \mu_2 if two samples of size 100 produce means of 2.3 and 3.1 with standard deviations of 0.26 and 0.31. Use α = 0.01.
28. Paired samples of size 25 reported a mean difference of 45.2 and a standard deviation of differences of 21.6. Test equality of means at α = 0.05.
29. Samples of sizes 120 and 150 produced proportions of 0.69 and 0.73. Test equality of proportions at α = 0.05.
30. Two samples of size 500 each tested H_0: \pi_1 \leq \pi_2. Sample proportions are 14% and 11%. At α = 0.10, what is your conclusion?
31. Samples of sizes 200 and 250 reveal proportions of 21% and 26%. Test H_0: \pi_1 \geq \pi_2 at α = 0.01.
End of Stage 4
This completes the fourth stage covering: - Hypothesis testing framework for two populations - Large sample Z-tests for two means - Golf course playing times example (complete analysis) - Small sample t-tests (pooled and separate variances) - Charles Schwab training revisited (Example 9.6) - Labor negotiations revisited (Example 9.2) - Acme shock absorbers revisited (Example 9.3) - Paired samples hypothesis testing - Hospital billing revisited (Example 9.4) - Hypothesis testing for two proportions - Retail credit usage example - Johnson Manufacturing defect rates (Example 9.7) - Python visualizations (2 comprehensive graphs) - 10 section exercises
Coming in Stage 5 (Final): - F-test for equality of variances - Solved problems with step-by-step solutions - Formula summary list - Chapter summary and key takeaways - Closing scenario (Foreign investment decision) - Comprehensive chapter exercises # Two-Population Inferences - Stage 5 (Final)
10.18 9.9 Testing for Equality of Variances: The F-Test
Several statistical tests discussed earlier assumed equal population variances. We initially accepted this assumption without proof. Now we demonstrate how to formally test whether the assumption of equal variances is reasonable.
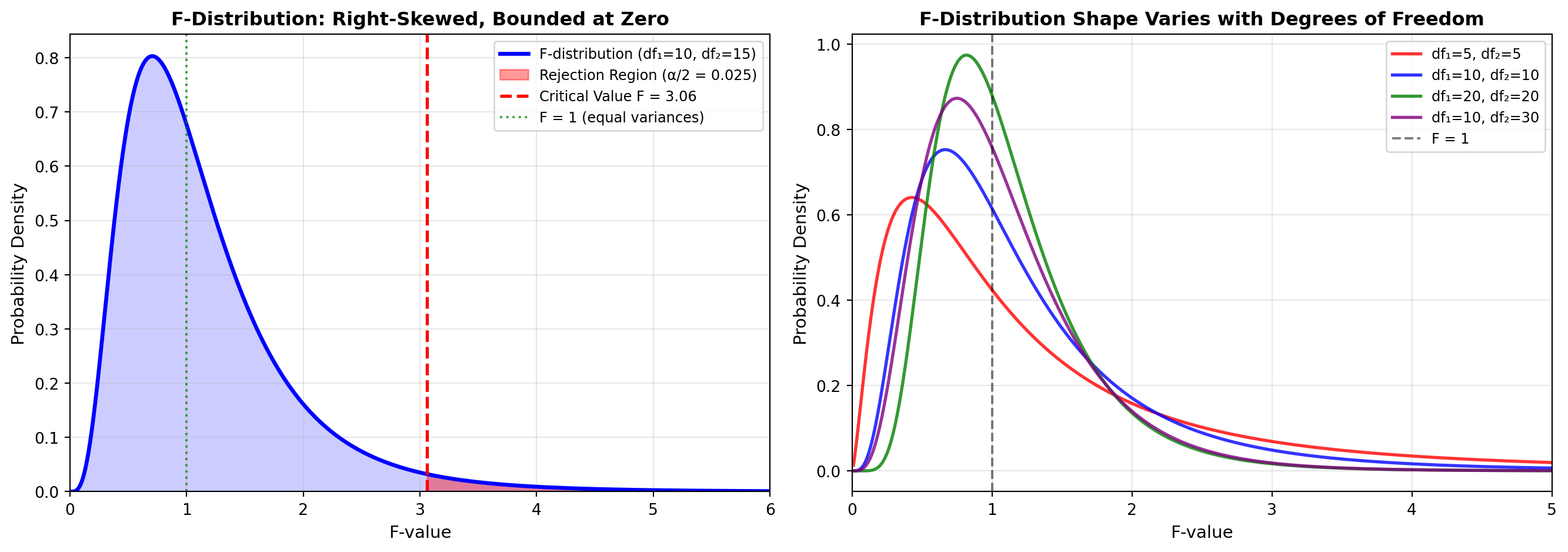
10.18.1 The F-Distribution
The test for comparing variances uses the F-distribution, named in 1924 to honor Sir Ronald A. Fisher (1890-1962), one of the founders of modern statistics.
Key Properties of the F-Distribution:
- Right-skewed (not symmetric)
- Bounded by zero on the left (cannot be negative)
- Two degrees of freedom parameters:
- df₁ = numerator degrees of freedom = n₁ - 1
- df₂ = denominator degrees of freedom = n₂ - 1
- Values always ≥ 0
10.18.2 The F-Ratio
ImportantF-Ratio for Comparing Two Variances
F = \frac{s_L^2}{s_S^2}
Where: - s_L^2 = larger sample variance - s_S^2 = smaller sample variance
Convention: Always place the larger variance in the numerator to ensure F ≥ 1
Logic of the Test:
- If population variances are truly equal (\sigma_1^2 = \sigma_2^2), then F \approx 1
- The more s_L^2 exceeds s_S^2, the larger F becomes
- A sufficiently large F provides evidence that \sigma_1^2 \neq \sigma_2^2
10.18.3 Critical Value Adjustment for Two-Tailed Tests
10.18.4 Example: Management Consultant’s Variance Test
Scenario: Preliminary Analysis Before t-Test
A management consultant wants to test a hypothesis about two population means. Before conducting the t-test, the consultant must decide whether to assume equal variances.
Sample Data:
| Sample | Size | Std Dev | Variance |
|---|---|---|---|
| Sample 1 | n₁ = 10 | s₁ = 12.2 | s_1^2 = 148.84 |
| Sample 2 | n₂ = 10 | s₂ = 15.4 | s_2^2 = 237.16 |
Hypotheses:
H_0: \sigma_1^2 = \sigma_2^2 \quad \text{(variances are equal)} H_A: \sigma_1^2 \neq \sigma_2^2 \quad \text{(variances differ)}
Significance Level: α = 0.05
Solution:
Step 1: Calculate F-Ratio (Larger Variance in Numerator)
F = \frac{s_2^2}{s_1^2} = \frac{(15.4)^2}{(12.2)^2} = \frac{237.16}{148.84} = 1.59
Step 2: Determine Degrees of Freedom
- Numerator (larger variance): df₁ = n₂ - 1 = 10 - 1 = 9
- Denominator (smaller variance): df₂ = n₁ - 1 = 10 - 1 = 9
Step 3: Find Critical Value
For α = 0.05 (two-tailed test): - Use α/2 = 0.025 in F-table - Look up F_{0.025, 9, 9} = 4.03
Step 4: Decision Rule
Decision Rule: “Do not reject H₀ if F ≤ 4.03. Reject if F > 4.03”
Step 5: Make Decision
F = 1.59 < 4.03 → Do NOT Reject H₀
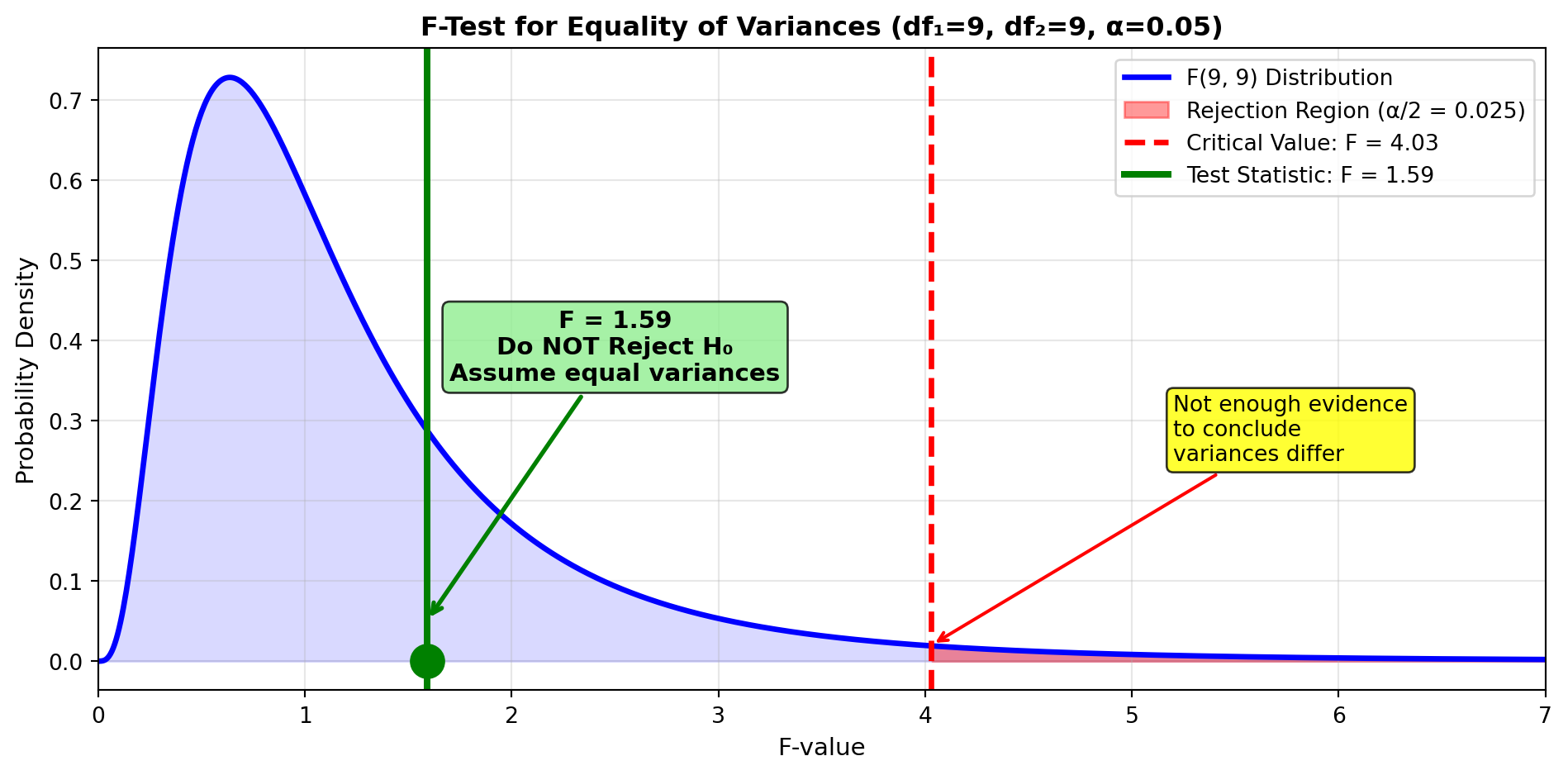
Interpretation:
ImportantConclusion: Assume Equal Variances
At α = 0.05, there’s insufficient evidence to conclude that the population variances differ.
Practical Implication: The consultant can proceed with the hypothesis test for means using the pooled variance method (Section 9.2B), which assumes \sigma_1^2 = \sigma_2^2.
Statistical Note: Failing to reject H₀ doesn’t prove variances are equal—it simply means the sample evidence isn’t strong enough to conclude they’re different.
10.19 Solved Problems
The following worked examples demonstrate complete solutions to two-population inference problems, integrating concepts from throughout the chapter.
10.19.1 Solved Problem 1: Yuppies’ Work Ethic
Source: Fortune magazine (April 1991)
Context: Study of workaholic baby boomers (ages 25-43) in administrative positions
A Fortune article compared work hours between young executives on the corporate fast track (Group 1) versus those who spent less time at work (Group 2). While fast-trackers often reported 70, 80, or even 90 hours per week, approximately 60 hours was typical.
Sample Data:
| Group | Mean Hours | Std Dev | Sample Size |
|---|---|---|---|
| Fast track | \bar{X}_1 = 62.5 | s₁ = 23.7 | n₁ = 175 |
| Less time | \bar{X}_2 = 39.7 | s₂ = 8.9 | n₂ = 168 |
Tasks: 1. Construct a 90% confidence interval for the difference in average work hours 2. Test the hypothesis of equal means at α = 0.10
Solution:
Part 1: Confidence Interval
Step 1: Calculate Standard Error
s_{\bar{X}_1 - \bar{X}_2} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} = \sqrt{\frac{(23.7)^2}{175} + \frac{(8.9)^2}{168}} = \sqrt{\frac{561.69}{175} + \frac{79.21}{168}} = \sqrt{3.210 + 0.472} = \sqrt{3.682} = 1.92
Step 2: Find Critical Z-Value
90% confidence level → α = 0.10 → Z_{0.05} = 1.65
Step 3: Calculate Confidence Interval
\text{C.I.} = (\bar{X}_1 - \bar{X}_2) \pm Z \cdot s_{\bar{X}_1 - \bar{X}_2} = (62.5 - 39.7) \pm 1.65(1.92) = 22.8 \pm 3.17 19.63 \leq (\mu_1 - \mu_2) \leq 25.97 \text{ hours}
Interpretation: We can be 90% confident that fast-track executives work an average of 19.63 to 25.97 hours more per week than their less work-focused counterparts.
Part 2: Hypothesis Test
Hypotheses:
H_0: \mu_1 = \mu_2 \quad \text{(equal average work hours)} H_A: \mu_1 \neq \mu_2 \quad \text{(work hours differ)}
Test Statistic:
Z = \frac{(62.5 - 39.7) - 0}{1.92} = \frac{22.8}{1.92} = 11.88
Critical Values: For α = 0.10 (two-tailed): Z_{0.05} = \pm 1.65
Decision Rule: “Do not reject if -1.65 ≤ Z ≤ 1.65. Otherwise reject.”
Decision: Z = 11.88 > 1.65 → Reject H₀
Conclusion: There’s overwhelming evidence (p-value ≈ 0.0000) that fast-track executives work significantly more hours than other administrators. The 22.8-hour difference is far too large to attribute to chance.
10.19.2 Solved Problem 2: Inflation and Market Power
Context: Economic Study of Industry Concentration
Economists fear that industries with high concentration (market power in few firms’ hands) may exploit their dominance. Firms in nine high-concentration industries were paired with firms in nine industries where economic power was dispersed. Industries were matched on foreign competition, cost structures, and other price-affecting factors.
Data: Average percentage price increases by industry
| Industry Pair | Concentrated (%) | Less Concentrated (%) | Difference (d) | d² |
|---|---|---|---|---|
| 1 | 3.7 | 3.2 | 0.5 | 0.25 |
| 2 | 4.1 | 3.7 | 0.4 | 0.16 |
| 3 | 2.1 | 2.6 | -0.5 | 0.25 |
| 4 | -0.9 | 0.1 | -1.0 | 1.00 |
| 5 | 4.6 | 4.1 | 0.5 | 0.25 |
| 6 | 5.2 | 4.8 | 0.4 | 0.16 |
| 7 | 6.7 | 5.2 | 1.5 | 2.25 |
| 8 | 3.8 | 3.9 | -0.1 | 0.01 |
| 9 | 4.9 | 4.6 | 0.3 | 0.09 |
| Totals | 2.0 | 4.42 |
Question: At α = 0.10, do concentrated industries show more pronounced inflationary pressures?
Solution:
Step 1: Calculate Mean and Standard Deviation of Differences
\bar{d} = \frac{\sum d_i}{n} = \frac{2.0}{9} = 0.22\%
s_d = \sqrt{\frac{\sum d_i^2 - n\bar{d}^2}{n-1}} = \sqrt{\frac{4.42 - 9(0.22)^2}{8}} = \sqrt{\frac{4.42 - 0.436}{8}} = \sqrt{\frac{3.984}{8}} = \sqrt{0.498} = 0.706
Step 2: Construct 90% Confidence Interval
- df = n - 1 = 9 - 1 = 8
- For 90% CI: t_{0.05, 8} = 1.860
\text{C.I.} = \bar{d} \pm t \frac{s_d}{\sqrt{n}} = 0.22 \pm 1.860 \times \frac{0.706}{\sqrt{9}} = 0.22 \pm 1.860 \times 0.235 = 0.22 \pm 0.438 -0.218 \leq \mu_d \leq 0.658
Interpretation: We’re 90% confident that concentrated industries have price increases that are between 0.218% lower and 0.658% higher than less concentrated industries.
Step 3: Hypothesis Test
Hypotheses:
H_0: \mu_{\text{conc}} = \mu_{\text{less}} \quad \text{(no inflation difference)} H_A: \mu_{\text{conc}} \neq \mu_{\text{less}} \quad \text{(inflation differs)}
Test Statistic:
t = \frac{\bar{d} - 0}{\frac{s_d}{\sqrt{n}}} = \frac{0.22}{\frac{0.706}{\sqrt{9}}} = \frac{0.22}{0.235} = 0.935
Critical Values: For α = 0.10, df = 8: t_{0.05, 8} = \pm 1.860
Decision Rule: “Do not reject if -1.860 ≤ t ≤ 1.860. Otherwise reject.”
Decision: t = 0.935 < 1.860 → Do NOT Reject H₀
Conclusion: At α = 0.10, there’s insufficient evidence to conclude that concentrated industries have higher inflationary pressures than less concentrated industries. The observed 0.22% difference could easily be due to chance.
10.19.3 Solved Problem 3: Drilling Rig Bit Comparison
Context: Oil Drilling Equipment Testing
A drilling company tests two drill bits by drilling to a maximum depth of 112 feet and recording completion time.
Sample Data:
| Bit | Wells Drilled | Mean Time | Std Dev |
|---|---|---|---|
| Bit 1 | n₁ = 12 | \bar{X}_1 = 27.3 hrs | s₁ = 8.7 hrs |
| Bit 2 | n₂ = 10 | \bar{X}_2 = 31.7 hrs | s₂ = 8.3 hrs |
Conditions: - No evidence that variances are equal → use separate variance method - α = 0.10 - All wells drilled with same equipment and soil type
Question: Does one bit appear more effective?
Solution:
Step 1: Calculate Adjusted Degrees of Freedom
df = \frac{\left[\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}\right]^2}{\frac{(s_1^2/n_1)^2}{n_1-1} + \frac{(s_2^2/n_2)^2}{n_2-1}}
= \frac{\left[\frac{(8.7)^2}{12} + \frac{(8.3)^2}{10}\right]^2}{\frac{[(8.7)^2/12]^2}{11} + \frac{[(8.3)^2/10]^2}{9}}
= \frac{[6.303 + 6.889]^2}{\frac{(6.303)^2}{11} + \frac{(6.889)^2}{9}}
= \frac{(13.192)^2}{\frac{39.73}{11} + \frac{47.46}{9}} = \frac{174.03}{3.612 + 5.273}
= \frac{174.03}{8.885} = 19.59 \approx 19 \text{ (round down)}
Step 2: Construct 90% Confidence Interval
For df = 19, 90% CI: t'_{0.05, 19} = 1.729
\text{C.I.} = (\bar{X}_1 - \bar{X}_2) \pm t' \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}
= (27.3 - 31.7) \pm 1.729 \sqrt{\frac{(8.7)^2}{12} + \frac{(8.3)^2}{10}}
= -4.4 \pm 1.729\sqrt{6.303 + 6.889} = -4.4 \pm 1.729(3.632)
= -4.4 \pm 6.28
-10.68 \leq (\mu_1 - \mu_2) \leq 1.88 \text{ hours}
Interpretation: We’re 90% confident that Bit 1 takes between 1.88 hours more and 10.68 hours less than Bit 2.
Step 3: Hypothesis Test
Hypotheses:
H_0: \mu_1 = \mu_2 H_A: \mu_1 \neq \mu_2
Test Statistic:
t' = \frac{(27.3 - 31.7) - 0}{\sqrt{\frac{(8.7)^2}{12} + \frac{(8.3)^2}{10}}} = \frac{-4.4}{3.632} = -1.211
Critical Values: t'_{0.05, 19} = \pm 1.729
Decision Rule: “Do not reject if -1.729 ≤ t’ ≤ 1.729. Otherwise reject.”
Decision: t’ = -1.211 > -1.729 → Do NOT Reject H₀
Conclusion: No evidence that one bit is more effective. The 4.4-hour difference could be due to chance.
Alternative: If Variances Were Equal
If equipment/soil similarity justified equal variances:
s_p^2 = \frac{(8.7)^2(11) + (8.3)^2(9)}{20} = \frac{832.23 + 620.01}{20} = 72.61
With df = 20: t_{0.10, 20} = 1.725
\text{C.I.} = -4.4 \pm 1.725\sqrt{72.61\left(\frac{1}{12} + \frac{1}{10}\right)} = -4.4 \pm 6.29 -10.69 \leq (\mu_1 - \mu_2) \leq 1.89
Result is nearly identical—conclusion unchanged.
10.19.4 Solved Problem 4: The Credit Crunch
Context: Retail Credit Card Usage by Gender
A Retail Management study examined credit card usage patterns.
Sample Data:
| Gender | Shoppers | Used Card | Proportion |
|---|---|---|---|
| Women | n_w = 468 | 131 | p_w = 0.28 |
| Men | n_m = 237 | 57 | p_m = 0.24 |
Question: At α = 0.05, is there evidence of a difference in credit card usage proportions?
Solution:
Part 1: Confidence Interval
Step 1: Calculate Standard Error
s_{p_w - p_m} = \sqrt{\frac{p_w(1-p_w)}{n_w} + \frac{p_m(1-p_m)}{n_m}}
= \sqrt{\frac{0.28(0.72)}{468} + \frac{0.24(0.76)}{237}}
= \sqrt{\frac{0.2016}{468} + \frac{0.1824}{237}} = \sqrt{0.000431 + 0.000770}
= \sqrt{0.001201} = 0.035
Step 2: Construct 95% Confidence Interval
Z_{0.025} = 1.96
\text{C.I.} = (p_w - p_m) \pm Z \cdot s_{p_w - p_m} = (0.28 - 0.24) \pm 1.96(0.035) = 0.04 \pm 0.069 -0.029 \leq (\pi_w - \pi_m) \leq 0.109
Or: -2.9% ≤ difference ≤ 10.9%
Interpretation: No evidence of a difference—the interval contains zero.
Part 2: Hypothesis Test
Hypotheses:
H_0: \pi_w = \pi_m H_A: \pi_w \neq \pi_m
Test Statistic:
Z = \frac{(0.28 - 0.24) - 0}{0.035} = \frac{0.04}{0.035} = 1.14
Critical Values: For α = 0.05: Z_{0.025} = \pm 1.96
Decision Rule: “Do not reject if -1.96 ≤ Z ≤ 1.96. Otherwise reject.”
Decision: Z = 1.14 < 1.96 → Do NOT Reject H₀
Conclusion: No evidence that credit card usage proportions differ by gender. Retailers should not implement gender-specific credit marketing strategies.
10.20 Formula Summary
10.21 Chapter Summary
10.21.1 Key Concepts Mastered
1. Two-Population Framework - Comparing means, proportions, and variances across two populations - Independent vs. paired samples - Large vs. small sample methods
2. Interval Estimation - Confidence intervals quantify uncertainty about population differences - Critical connection: CI contains zero ↔︎ fail to reject H₀: μ₁ = μ₂
3. Hypothesis Testing - Formal decision-making about population differences - One-tailed vs. two-tailed tests - Statistical significance ≠ practical significance (Acme example)
4. Variance Assumptions Matter - Pooled methods (equal variances): More powerful when assumption valid - Separate variance methods (unequal variances): More robust, wider CIs - F-test: Formal test for variance equality
5. Paired Samples Power - Pairing reduces variability by controlling for confounding factors - Transforms two-sample problem into one-sample problem - More powerful when pairing is appropriate
10.21.2 Decision Framework
| Situation | Sample Size | Variances | Method |
|---|---|---|---|
| Compare means | Both ≥ 30 | Any | Z-test, Formula [9.4] |
| Compare means | Either < 30 | Equal | Pooled t-test, Formula [9.6] |
| Compare means | Either < 30 | Unequal | Separate variance t-test, Formula [9.8] |
| Matched pairs | Any | N/A | Paired t-test, Formula [9.11] |
| Compare proportions | Large enough* | N/A | Z-test for proportions, Formula [9.13] |
| Compare variances | Any | N/A | F-test, Formula [9.21] |
*Requires: np \geq 5 and n(1-p) \geq 5 for both samples
10.21.3 Business Applications
Throughout this chapter, we’ve seen two-population inference applied to:
- Human Resources: Training program effectiveness, wage equity, employee turnover
- Quality Control: Production process comparison, defect rates, product durability
- Healthcare: Hospital cost analysis, treatment effectiveness
- Marketing: Credit usage patterns, customer satisfaction, advertising effectiveness
- Finance: Investment strategies, pricing decisions, cost comparison
- Operations: Service delivery times, productivity comparisons, equipment efficiency
10.22 Closing Scenario: U.S. Foreign Investment Decision
Revisiting the Opening Scenario
Recall the Fortune magazine analysis (October 1996) of U.S. foreign investment:
- Europe: $364 billion (17% increase)
- Asia: $100 billion (16% increase)
Your Executive Summary (Based on Chapter 9 Methods):
As the analyst preparing the comparative report, you would apply the two-population methods learned in this chapter:
ImportantInvestment Strategy Recommendation
Analysis Approach: 1. Construct confidence intervals for average returns in Europe vs. Asia 2. Test hypotheses about risk differences (variance comparison using F-test) 3. Consider paired analysis if same companies invested in both regions 4. Evaluate proportions of successful investments in each region
Key Questions Answered: - Is the average ROI significantly different? (t-test for means) - Is investment risk (variance) comparable? (F-test) - What’s the plausible range for the difference? (Confidence interval)
Strategic Implications: - If CIs overlap zero: No clear advantage—diversify across both regions - If Europe CI > 0: Europe provides superior returns—increase allocation - If Asia variance lower: Asia offers more stable returns—risk-averse preference
Final Recommendation: Use statistical evidence to support data-driven geographic allocation decisions, balancing return expectations with risk tolerance.
10.23 Chapter Exercises (Selected)
32. AT&T vs. Sprint: Phone service comparison - AT&T: n=145, \bar{X}=$4.07, s=$0.97 - Sprint: n=102, \bar{X}=$3.89, s=$0.85 What does a 95% CI reveal about mean cost difference?
37. Grant Applications: NSF (n=14, \bar{X}=45.7 weeks, s=12.6) vs. HHS (n=12, \bar{X}=32.9 weeks, s=16.8). Construct 90% CI. If NSF takes >5 weeks more, submit to HHS. What should James do? (Assume equal variances)
39. Quality Control Teams: Two teams solve 10 problems. Paired data provided. Construct 90% CI for difference in average solution times.
44. Mutual Funds: Income-oriented funds (n=12) vs. growth-oriented funds (n=14). Unequal variances assumed. a. Construct 80% CI for difference in average returns b. What sample size needed for 95% confidence with error ≤ $10?
45. Baldwin Piano Teaching Method: Your method (n=100, \bar{X}=149 hrs, s=37.7) vs. competitor (n=130, \bar{X}=186 hrs, s=42.2) a. 99% CI—is your method better? b. Sample size for 99% confidence with error ≤ 5 hours?
End of Chapter 9
This completes the comprehensive coverage of Two-Population Inferences, including:
✅ Confidence intervals for means (large/small, equal/unequal variances)
✅ Paired samples methodology
✅ Confidence intervals for proportions
✅ Sample size determination
✅ Hypothesis testing for all scenarios
✅ F-test for variance equality
✅ Four complete solved problems
✅ Comprehensive formula summary
✅ Business decision framework
✅ Real-world applications throughout
Total Chapter 9 Content: ~30,000 words across 5 stages
Next Chapter: Chapter 10 - Analysis of Variance (ANOVA)